糖尿病预测
案例介绍
本案例使用Pima印第安人的糖尿病数据,分析糖尿病与怀孕次数、年龄等特征的相关关系。
数据集介绍
数据来源于https://www.kaggle.com/uciml/pima-indians-diabetes-database
数据集下载:diabetes.csv
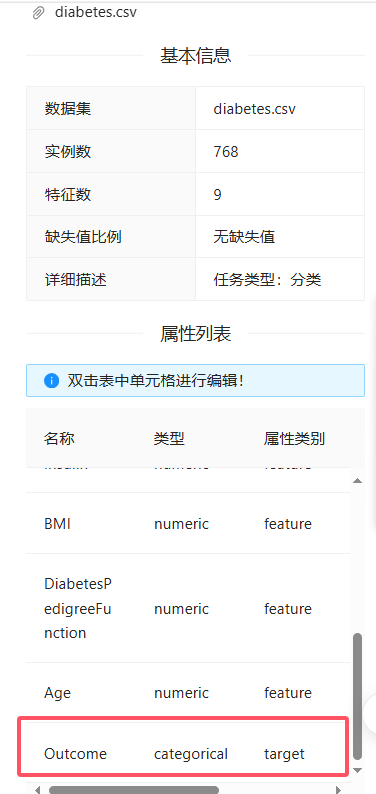
该数据集包含9个字段,具体说明如下表所示
| 字段 | 说明 |
|---|---|
| Pregnancies | 怀孕的次数 |
| Glucose | 血浆葡萄糖浓度,采用2小时口服葡萄糖耐量实验测得 |
| BloodPressure | 舒张压(毫米汞柱) |
| SkinThickness | 肱三头肌皮肤褶皱厚度(毫米) |
| Insulin | 两个小时血清胰岛素(μU/毫升) |
| BMI | 身体指数,体重除以身高的平方 |
| Diabetes Pedigree Function | 糖尿病血统指数,糖尿病和家族遗传相关 |
| Age | 年龄 |
| Outcome | 目标值,表示糖尿病检测结果,0:阴性,1:阳性 |
案例操作
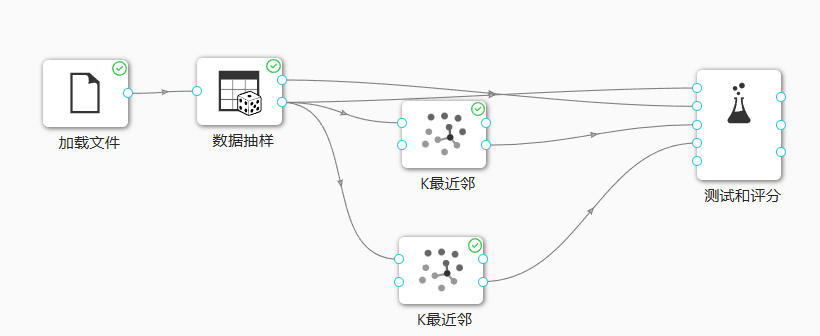
通过观察数据的特征我们可以得知:目标是一个离散属性,因此我们可以选择分类算法来实现本案例的需求。我们使用普通的K最近邻算法和带权重的K最近邻算法分别对数据集进行拟合并计算模型得分,工作流如下图所示,最后选择效果更好的模型来完成本案例。
1、使用“加载文件”组件加载数据集,在“手动上传”tab页点击“选择文件”来上传本案例所需数据集,并设置属性【Outcome】的属性类别为“target”,即目标属性,类型为“categorical”。
2、为了评估模型的性能和泛化能力,我们还需将数据划分为训练集和测试集。其中训练集用于训练模型,测试集用于评估模型在未知数据上的表现,避免过拟合。“数据抽样”方便用户把一个数据拆分为两个集合(抽样数据及剩余数据),拆分后的数据其中一个可用于模型训练即作为训练集,另一个可作为测试集使用。我们使用该组件来对数据进行拆分。
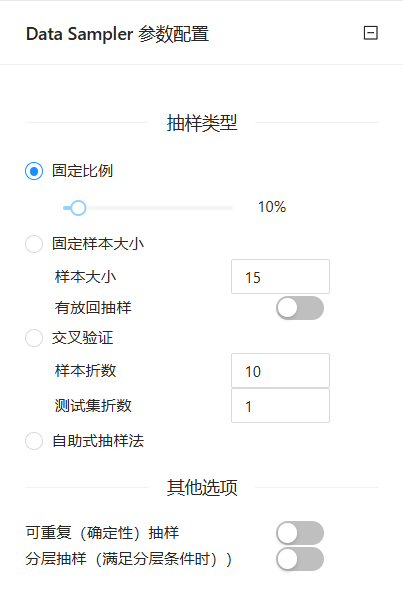
下图为“数据抽样”组件的参数设置,我们选择“固定比例”进行抽样,我们使用默认值10%作为抽样比例。
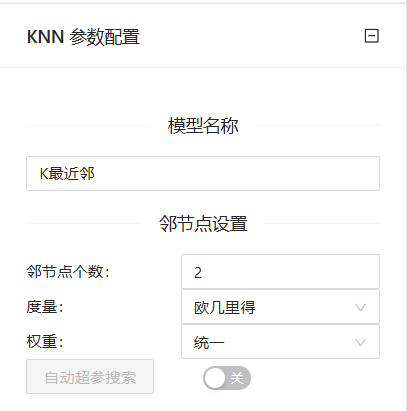
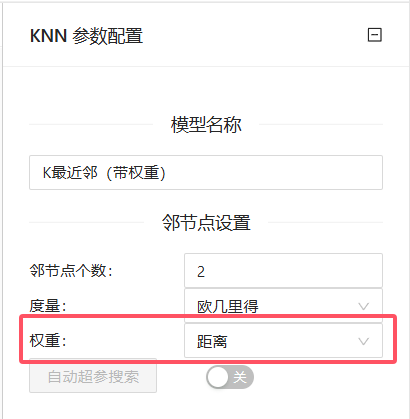
3、将数据处理好之后我们就需要将其传送给模型来进行糖尿病预测。我们配置两个“K最近邻”组件来进行效果对比,参数设置如下图所示
4、最后我们还需对模型的性能进行一系列评估。运行“测试和评分”组件,交叉验证的折数为10,即把数据分成10份,其中1份作为交叉验证数据集来计算模型准确信个,剩余的9份作为训练数据集。得到评估结果如下图所示。我们发现两个算法的大多数性能指标都差不多,召回率的差距较大。
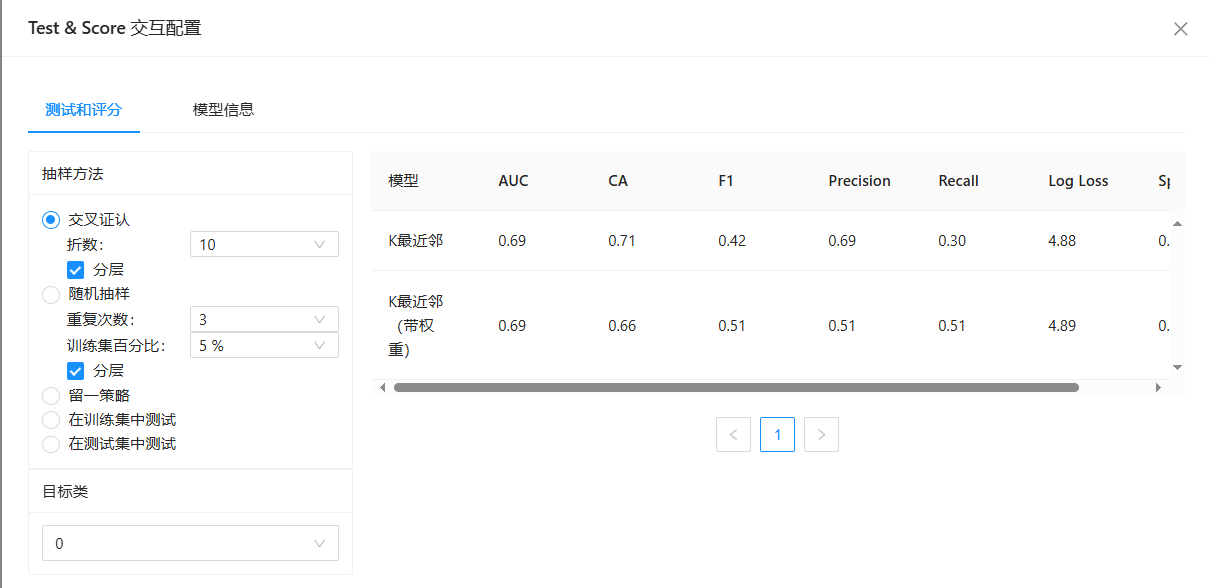
综合来看,带权重的K最近邻算法的性能要更优一些。接下来,我们就使用带权重的K最近邻算法对数据集进行训练,并查看对训练样本拟合情况以及对测试样本的预测准确性情况,工作流如下图所示:
1、使用“加载文件”组件加载数据集,在“手动上传”tab页点击“选择文件”来上传本案例所需数据集,并设置属性【Outcome】的属性类别为“target”,即目标属性,类型为“categorical”。
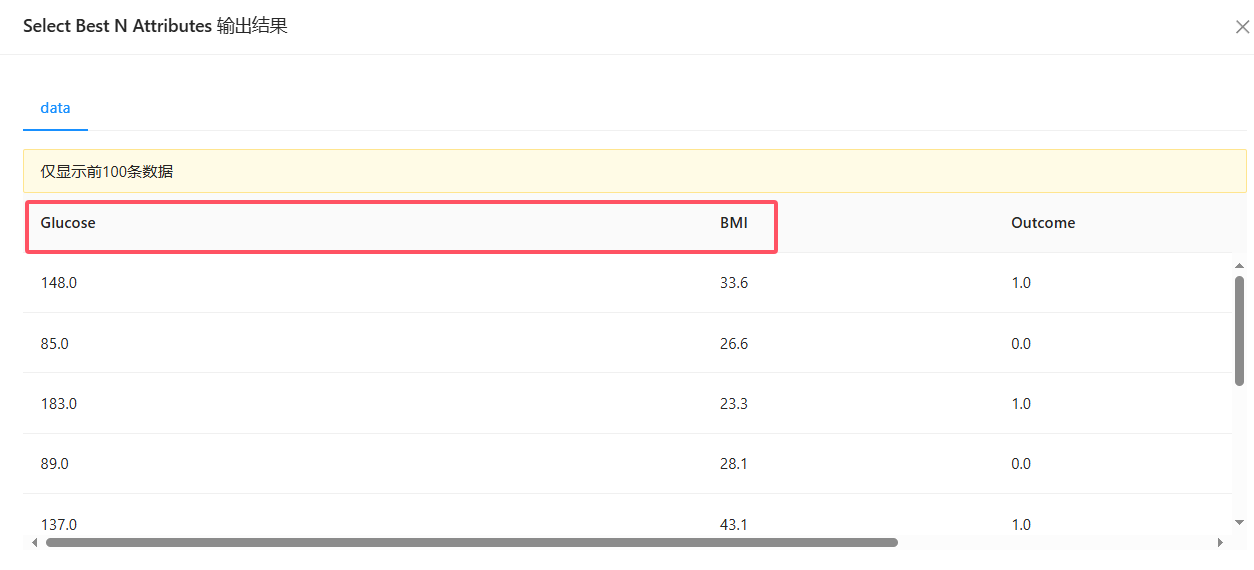
2、在建模过程中,读者可能会问,有没有直观的方法,能描述特征对模型的贡献度呢?一个办法是把数据画出来,可是本案例有8个特征,无法在这么高的维度里面画出数据,并直观地观察。另一个解决办法就是特征选择,即只选择2个与模型性能相关性最大的特征,这样就可以在二维平面上画出特征与模型性能的关系了。“自动特征选择”组件则是计算一般特征与目标特征的相关性,选出最相关的N个属性。
点击“自动特征选择”组件,设置自动筛选的属性个数N为2,运行该组件得到的两个特征为:【Glucose】和【BMI】。其他组件参数参考前一节。

3、使用“数据抽样”组件对数据进行拆分,配置如下图所示。
4、由于带权重的K最近邻算法的性能要更优一些,我们配置带权重的“K最近邻”组件来进行模型训练,参数设置如下图所示
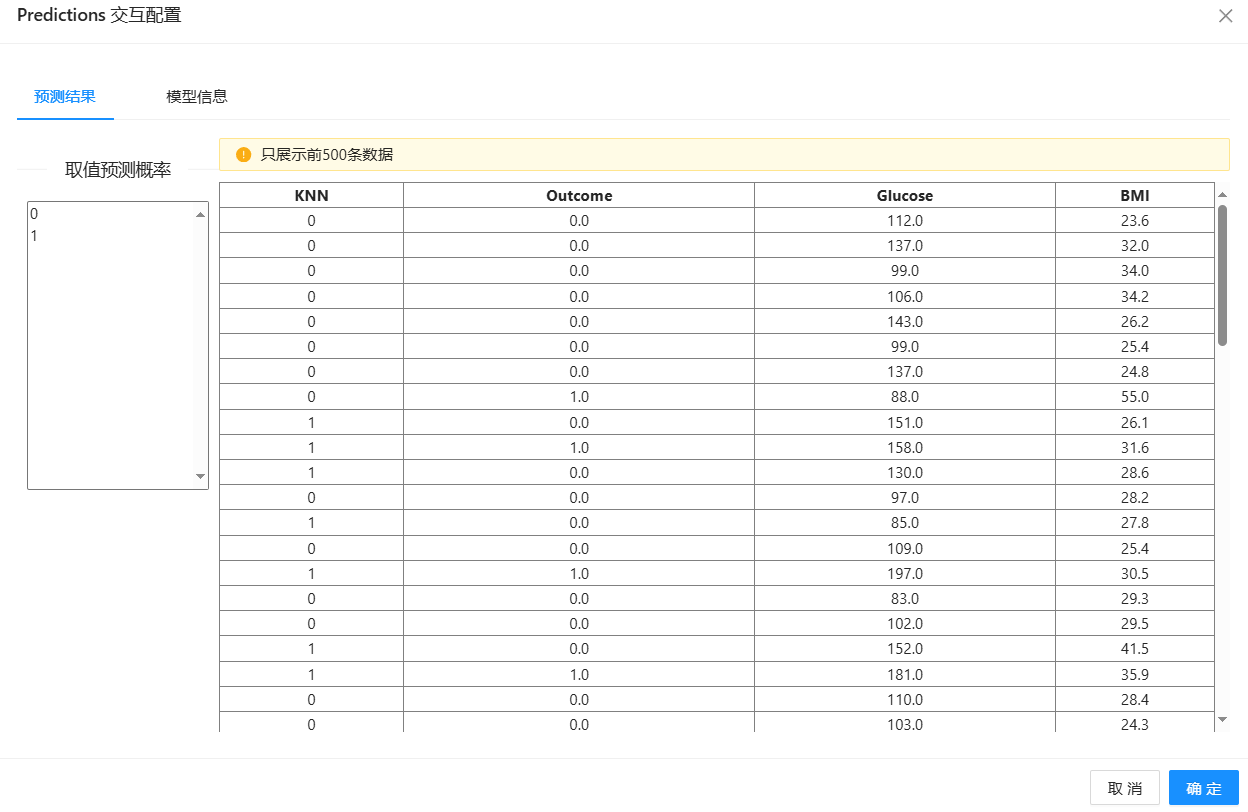
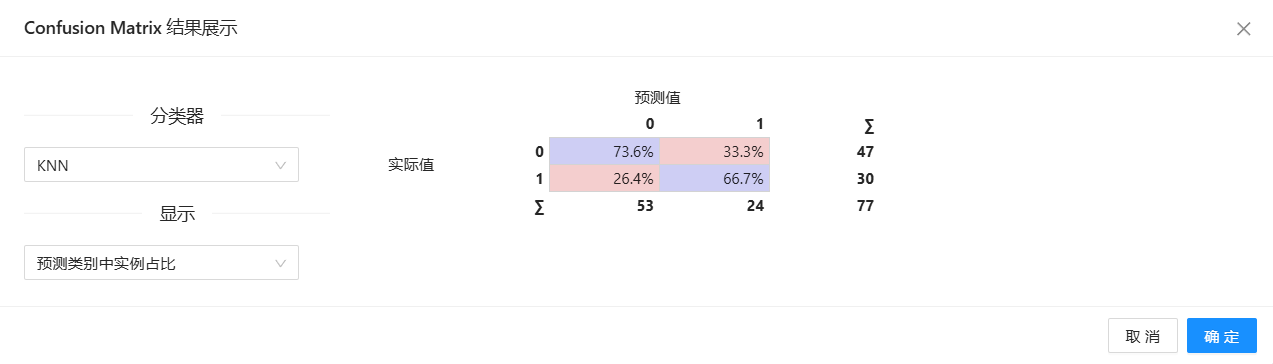
5、运行“预测”组件得到预测结果,然后运行“混淆矩阵”组件得到混淆矩阵如下图所示,此时由�两个特征构建的模型的准确率为67%左右。
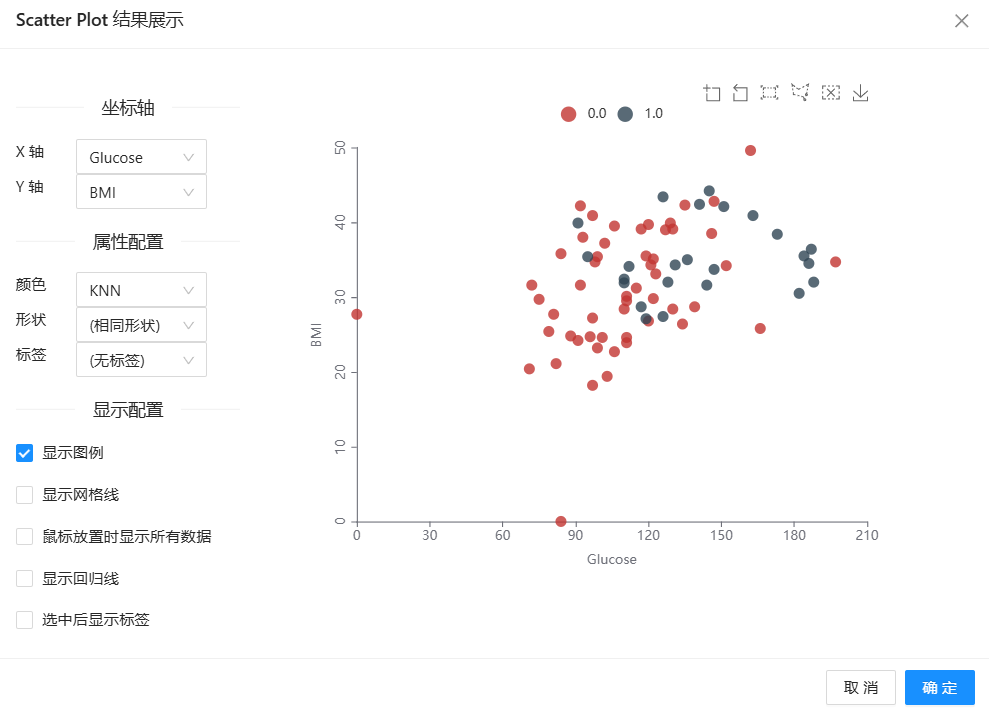
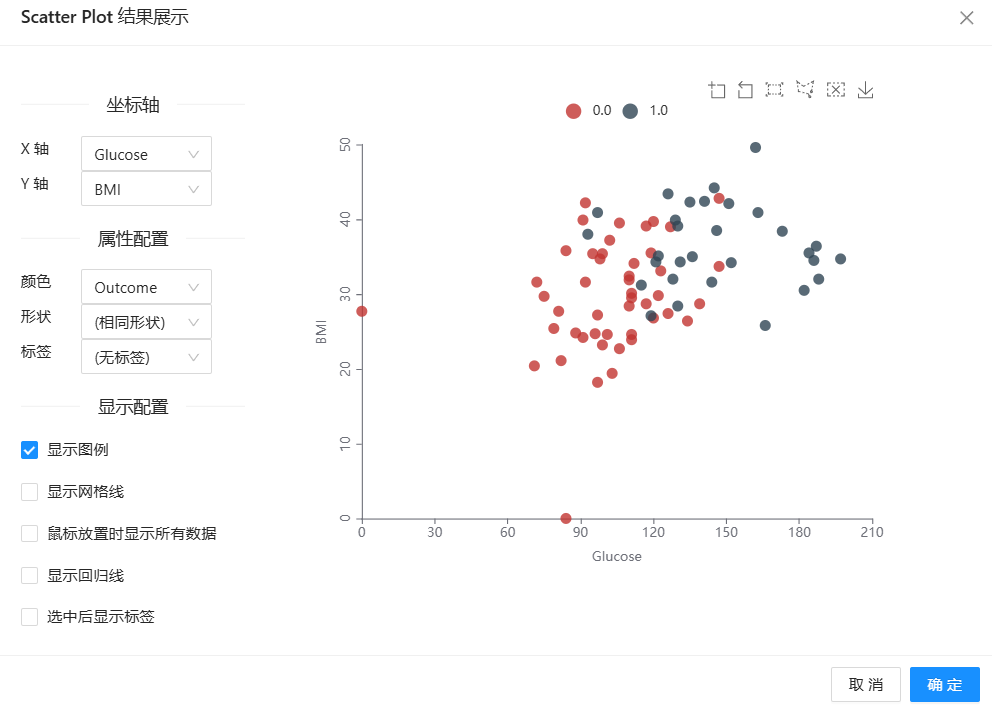
6、最后运行“散点图”组件,得到如下图所示的两幅散点图,上图为预测的结果,下图为实际的结果。从图中我们发现以【Glucose】和【BMI】特征来反映身体肥胖情况,在中间数据集密集的区域,阳性样本和阴性样本几乎重叠在一起了。假设现在有一个带预测的样本在中间密集区域,它的阳性邻居多还是阴性邻居多呢?这真的很难说。这样就可以直观地看到,K最近邻算法在糖尿病预测问题上,无法达到很高的预测准确性。