增量抽取
案例说明
- 什么是CDC?它的作用是什么?
ETL过程的第一步就是从不同的数据源抽取数据并把数据存储在数据缓存区。这个过程的主要挑战就是初始加载的数据量大和比较慢的网络延迟。在初始加载完成后,不能再把所有数据重新加载一遍。我们只需要抽取变化的数据。识别出变化的数据并只抽取这些变化的数据称为变化数据捕获(Change Data Capture)或CDC。
- CDC种类的划分
1 侵入性的(指CDC操作可能会给源系统带来性能的影响)
- 基于时间戳的CDC:这种方法至少需要一个更新时间戳,但最好有两个时间戳:一个插入时间戳(记录什么时候创建)和一个更新时间戳(记录什么时间最后一次更新)。
- 基于触发器的CDC
- 基于快照的CDC
2 非侵入性的
- 基于日志的CDC
数据准备
本案例中“基于时间戳的CDC”小节将使用cdc_time.sql、customers.sql、customers1.sql数据;
本案例中“基于快照的CDC”小节将使用customers2.sql、customers.sql数据;
以上数据文件均从“UDI Studio 平台”的“公共空间”里面获取
基于时间戳的CDC
本小节将介绍的是一个包含了三个转换的作业:
第一个转换获得当前时间并更新时间戳(current_load);
第二个转换从客户表(customer)中抽取出在上次抽取时间戳(last_load)和本次抽取时间戳(current_load)之间的增量数据;
第三个转换将current_load时间戳赋值给last_load时间戳,更新数据的最后一次更新时间,
完整工作流如下图所示:
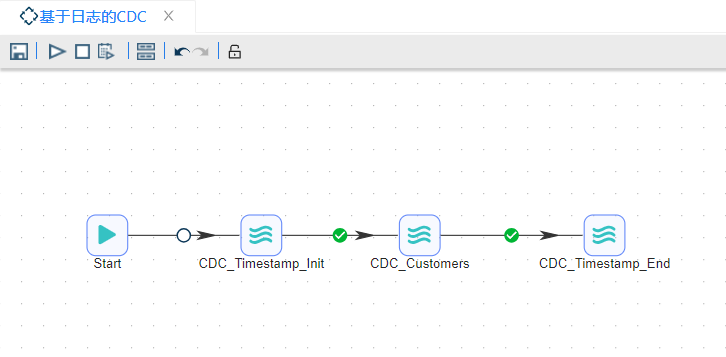
具体操作如下:
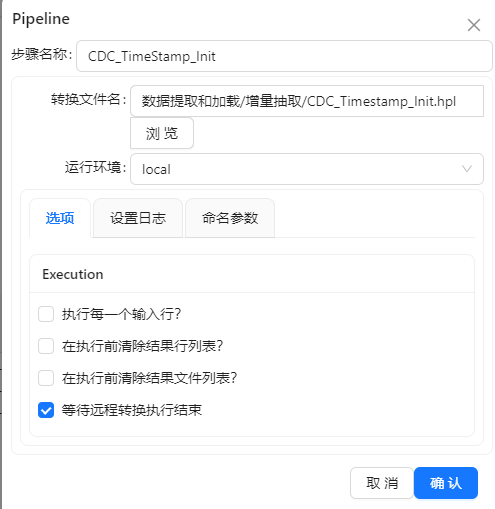
转换一:CDC_Timestamp_Init.hpl
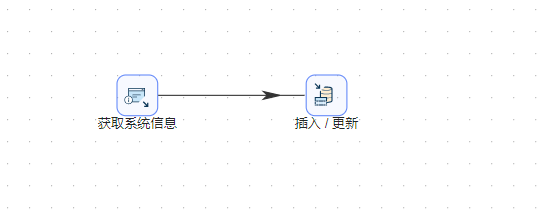
转换的总览如下图所示:
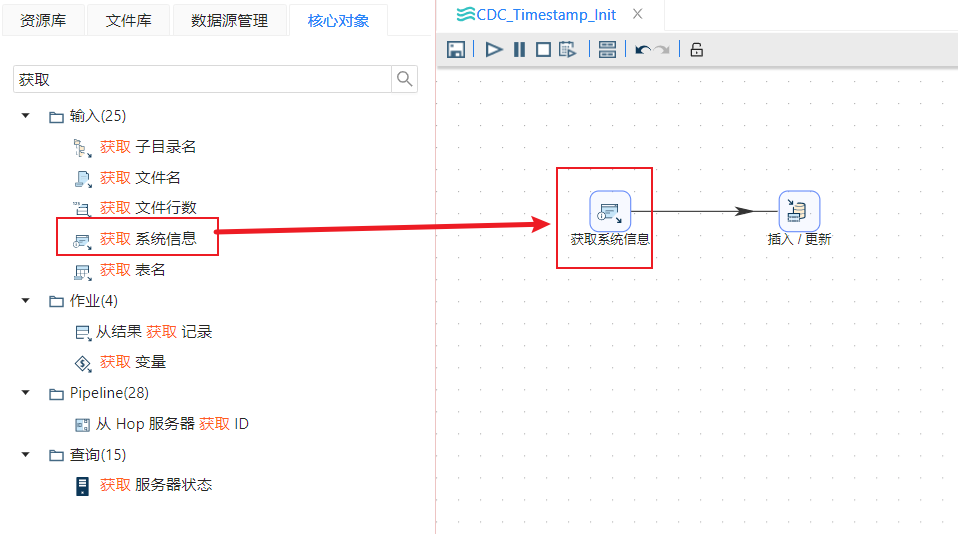
- 新建转换,通过获取系统信息组件获取当前执行数据更新任务的时间:从输入类组件中选择“获取系统信息”组件,如下图所示:
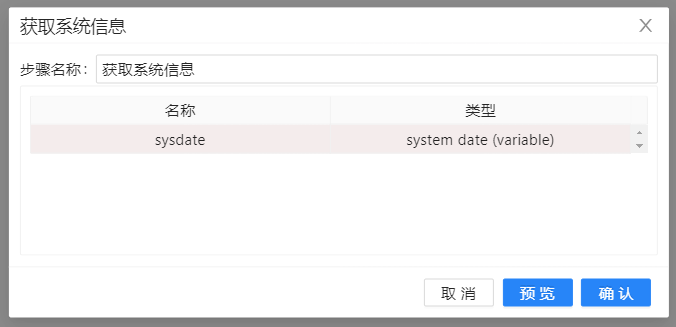
- 双击组件进行编辑,创建一个 “系统日期(可变)”类型的字段,字段名是sysdate。该组件可以获取转换执行时的系统时间并记录在sysdate字段中。点击确定保存。如下图所示:
- 创建一个“插入/更新 ”步骤,把“获取系统信息”步骤和“插入/更新”连接起来。如下图所示:
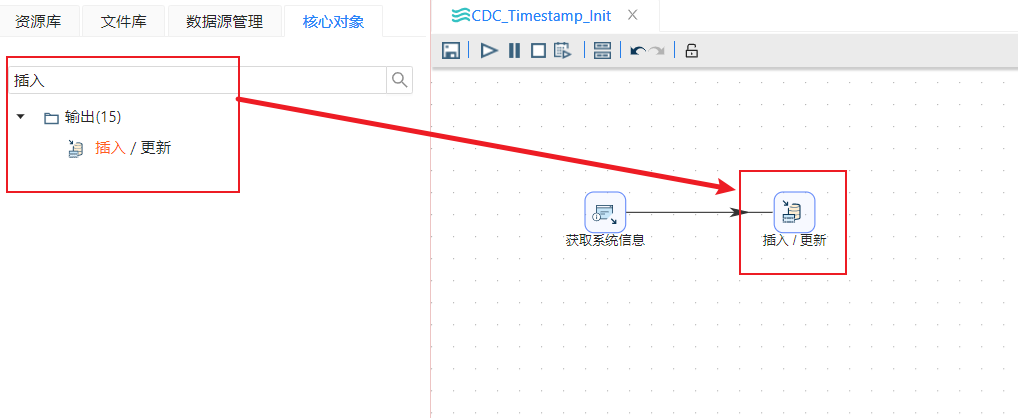
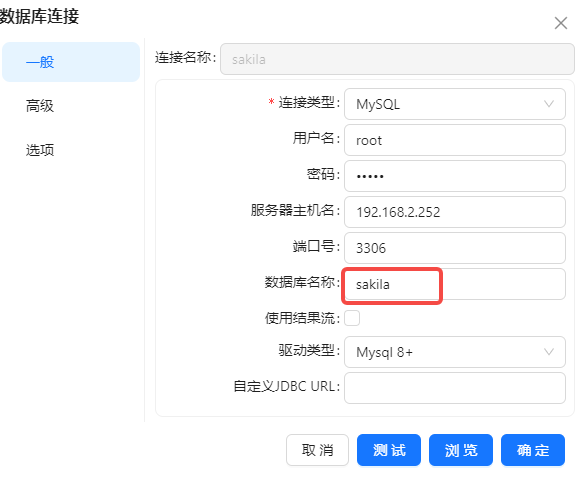
- 在“插入/更新”步骤的“基本配置”部分里,点击新建创建一个到sakila_dwh库的数据库连接,点击确定保存,然后点击浏览选中数据库中的cdc_time表,如下图所示:
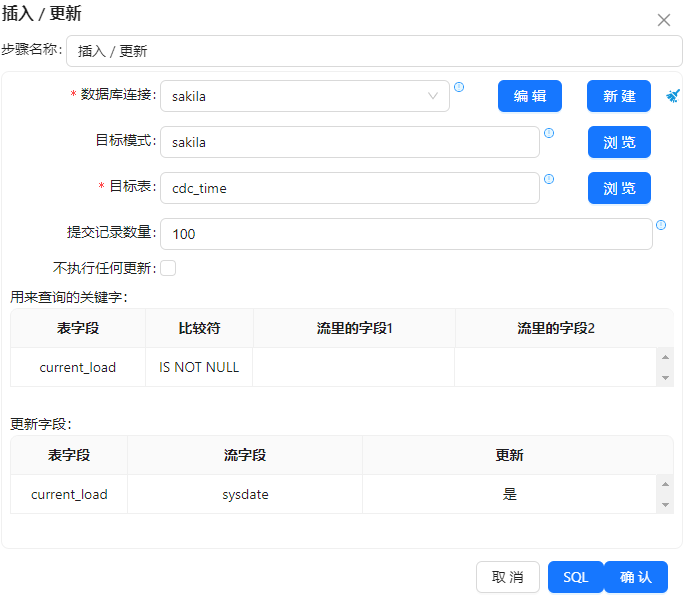
5 在“插入/更新”步骤的“更新字段”部分里,用数据流里的字段“sysdate”去更新表里的字段“current_load”。另外还要设置查询字段部分,把表的“current_load”的条件设置为“IS NOT NULL”即可(不设置查询条件的话,步骤会报错)。如下图所示:
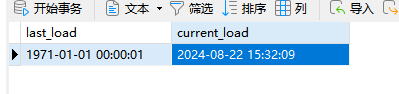
6 转换执行成功后,刷新sakila_dwh库中的”cdc_time表“会发现”current_load“字段已经更新为转换执行时的时间,如下图所示:
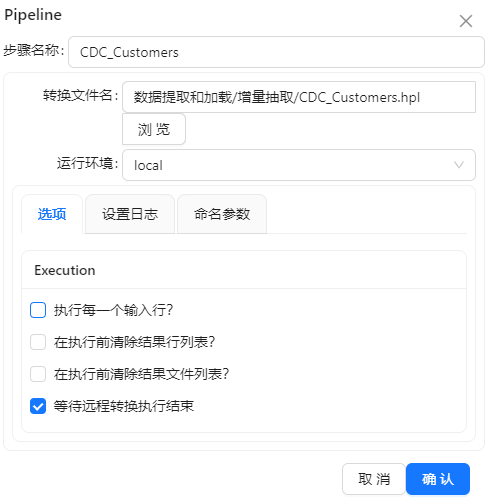
转换二:CDC_Customers.hpl
这里需要两个表输入步骤,一个用来从cdc_time表中抽取时间,另一个从Customer表中抽取需要的数据。customer表中同样有插入时间和更新时间字段,要想从customer表中抽取出最新的数据,查询条件就应该这样写:
SELECT *
FROM customer
WHERE
(create_date >= ? AND create_date < ?)
OR
(last_update >= ? AND last_update < ?)
这里的四个参数需要通过上一个表输入步骤传递过来,另外再看查询条件,可以发现last_load和current_load分别出现两次。就是说在第一个表输入步骤中,这些时间值需要被抽取出来两次。sql如�下:
SELECT
last_load last1
, current_load cur1
, last_load last2
, current_load cur2
FROM cdc_time
转换的总览如下图所示:
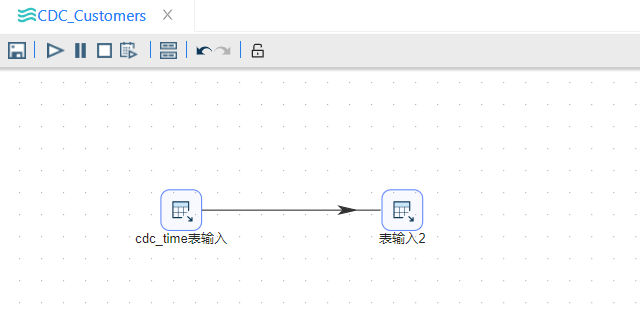
具体操作步骤如下:
1 新建转换,从输入栏中拖动“表输入”组件,命名为“cdc_time表输入”,“cdc_time表输入”配置如下图所示:
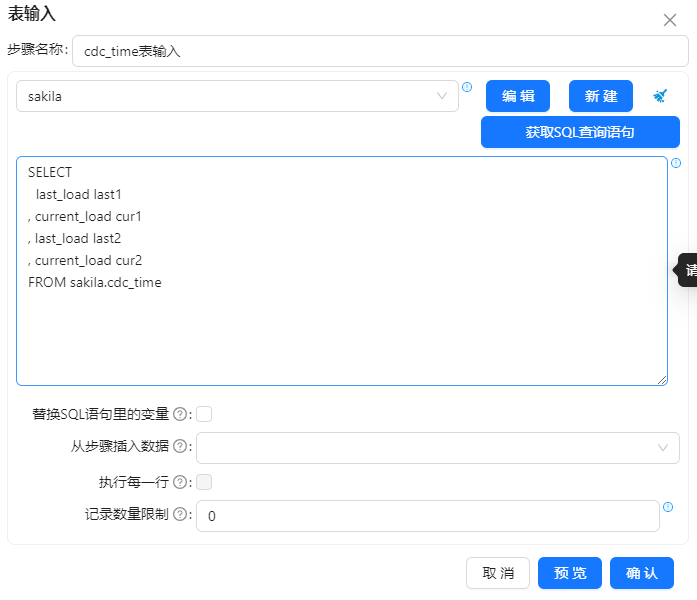
2 再次拖动一个“表输入组件”,和“cdc_time表输入”步骤连接起,选中从"cdc_time表输入步骤"中插入数据,这样获取的就是位于两个时间戳之间的增量数据,如下图所示:
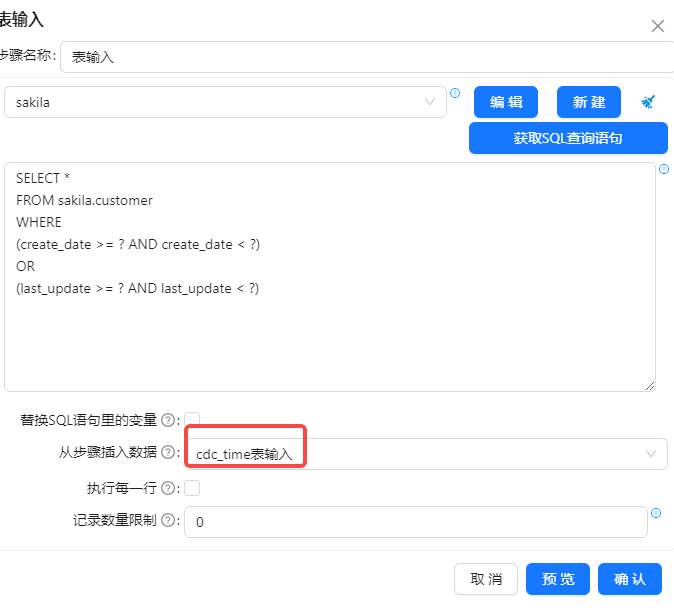
3 再次拖动一个“删除组件”,和“表输入”步骤连接,因为要把获取的增量数据插入customer1表中,得先把该表中的原有数据清空,具体配置如下图所示:
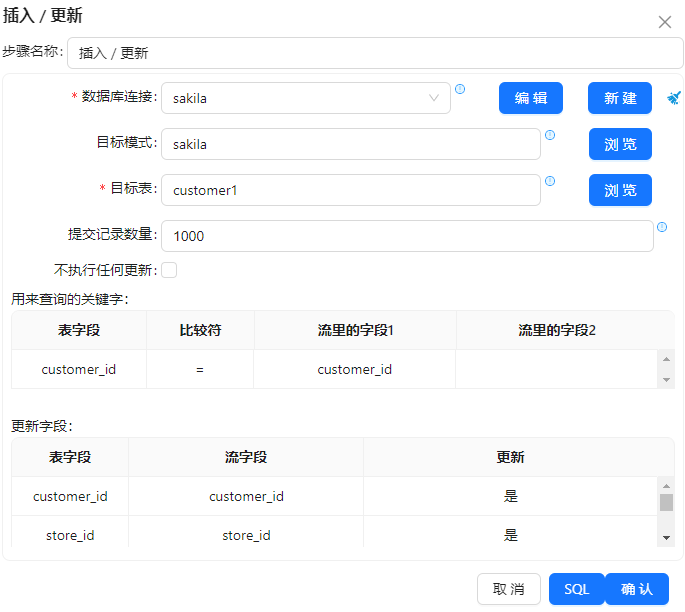
4 再次拖动一个“插入/更新组件”,和“删除组件”步骤连接起,把获取的位于两个时间戳之间的增量数据插入“customer1”表中,具体配置如下图所示:
5 点击画布左上角“ ”按钮运行转换,并在弹出的提示框中点击“启动”按钮,即可运行整个转换。结果如下图所示:
”按钮运行转换,并在弹出的提示框中点击“启动”按钮,即可运行整个转换。结果如下图所示:
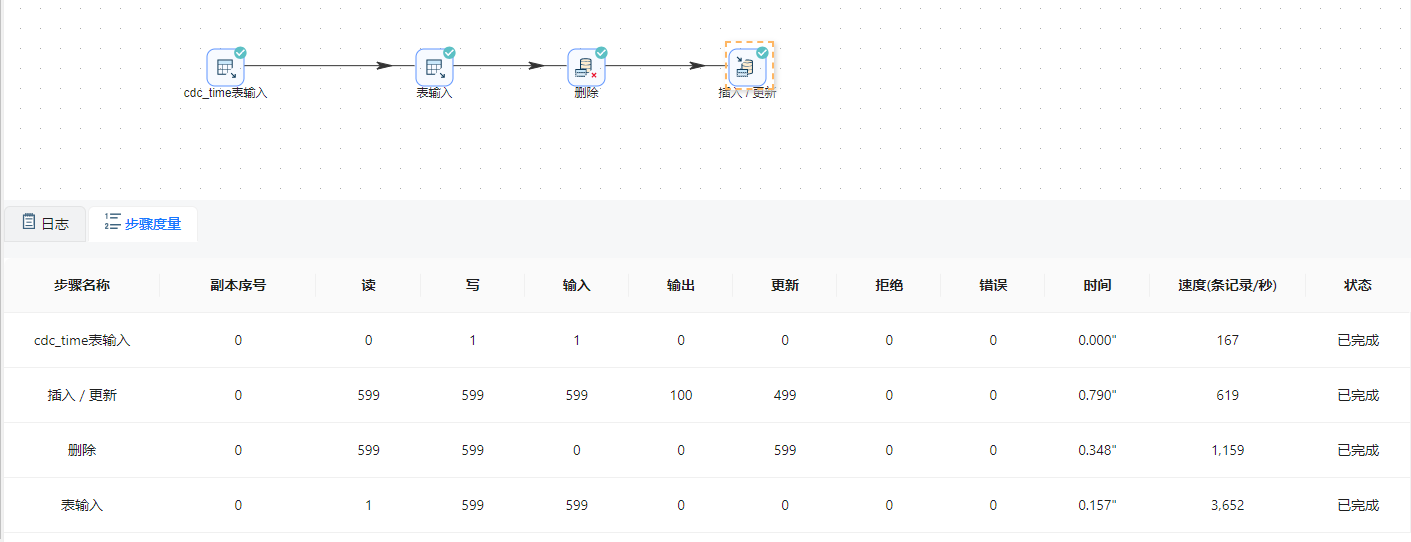
6 可以查看"customer1表"中是否有新的数据,如下图所示:
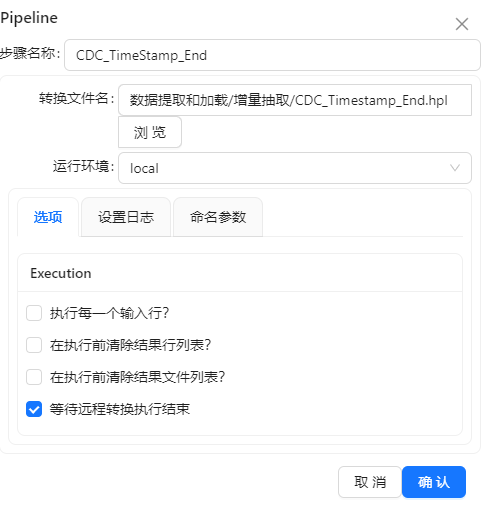
转换三:CDC_Timestamp_End.hpl
转换的总览如下图所示:
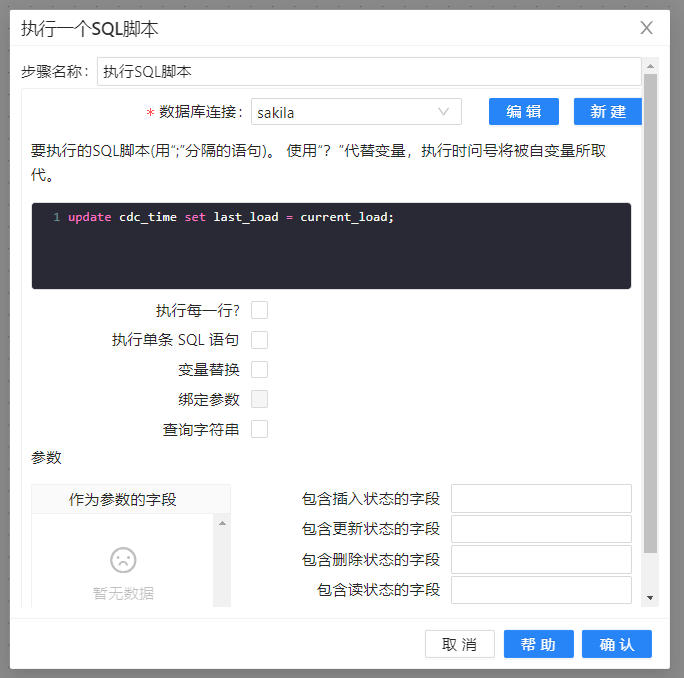
1、新建转换,如果转换中没有发生任何错误,要把current_load字段里的值复制到last_load字段里。如果转换中发生了错误,时间戳需要保持不变。把current_load字段里的值复制到last_load字段里需要“执行SQL脚本”步骤,脚本如下:
update cdc_time set last_load = current_load;
2 更新sakila_dwh库中的cdc_time表的last_load字段,配置数据库连接,写入要执行的sql语句(如果是多个语句要用分号分隔开)即可,如下图所示:
基于时间戳的CDC.hwf
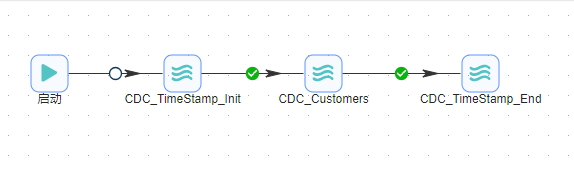
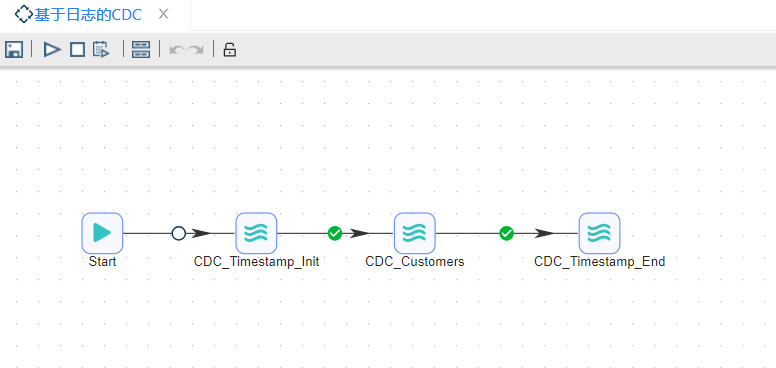
1 在完成了前面的三个转换后,可以用一个作业将这三个转换连接起来。新建作业,从输入栏中拖入3个“Pipeline”组件,分别命名为“CDC_TimeStamp_Init”、“CDC_Customers”和“CDC_TimeStamp_End”,START步骤是每一个作业的起点,一个作业必须要有一个START步骤,从START步骤到下一个步骤的跳上会有一个锁的标记,意思是不管怎样,这个步骤都将执行,后面的跳上会有一个绿色的√,意思是上一个步骤执行无误的话就会执行下一个步骤,具体配置如下图所��示:
2 点击画布左上角“”按钮运行转换,并在弹出的提示框中点击“启动”按钮,即可运行整个转换。结果如下图所示:
基于快照的CDC
如果没有时间戳,可以使用快照表,通过比较来获得变化。快照表是一次性抽取源系统中全部数据,把这些数据加载到数据仓库的缓冲区中,下一次需要同步时,再从源系统中抽取全部数据,并把全部数据也放到数据仓库的缓冲区中,作为这个表的第二个版本,然后再比较这两个版本的数据,找到变化。
目前,大部分ETL工具都可以比较两个表之间的差异,并增加一个字段,人们一般更喜欢使用这种 ETL 功能而不是 SQL 语句来比��较两个表的差异。Uniplore 里的**“合并记录”**步骤也有这个功能。这个步骤读取两个使用关键字排序的输入数据流,并基于数据流里的关键字比较其他字段。可以选择要比较的字段,并设置一个标志字段,作为比较结果输出字段。
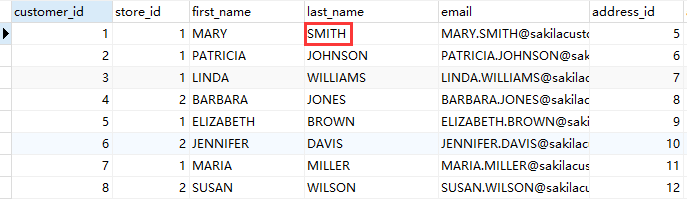
本节将利用 sakila 数据库里的表为例,先把这个表里的全部数据抽取出来,再修改源表里的几条记录,便可以创建基于快照的 CDC 转换。具体操作如下: 1、先把 数据库“sakila”里的“customer表” 里的全部数据保存在另一个数据库“sakila_dwh”里的 “customer2 表”中,也可以直接保存在 sakila 库里。但在实际场景中,一般不允许直接保存在源数据库系统或数据仓库中。所以最好保存在缓冲数据库中(该例子就将customer2保存在“sakila_dwh缓冲数据库”中)。对原来的数据做一些修改,例如改变【last_name】字段,使一个用户失效,或添加新的用户,这些都要在源数据库系统上进行修改,修改【last_name】将“SMITH”改为“RIOS”, 如下图所示:
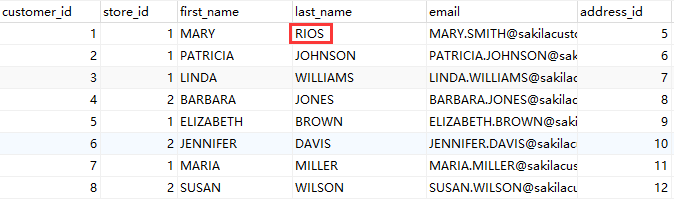
为了 Uniplore 能检测出删除的数据,可以在 customer2 表里增加一行,这行在源系统中不存在,这样可以模拟出在源系统中删除一条的情况;

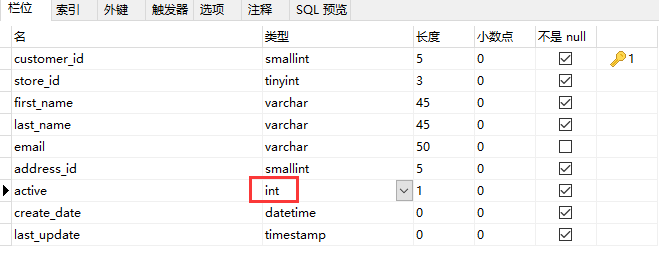
2、还需要将这些数据库表中的 active 字段修改为 int 类型,否则 Uniplore 将�会自动识别成 boolean 类型,运行时会报错;
3、新建转换,将 “表输入”组件拖两次至画布,并分别命名为“customer表输入”和“customer2表输入”,一个是 sakila 库的源表“customer表”表输入,另一个是 sakila 库的“customer2表”表输入,并需要选中所有字段。双击组件,在弹出的对话框中选择数据库连接,单击 “获取SQL查询语句”,在对应的文本框中即可获得对应表的查询。当然,也可以在文本框中编写自定义SQL查询语句。配置如下图所示:
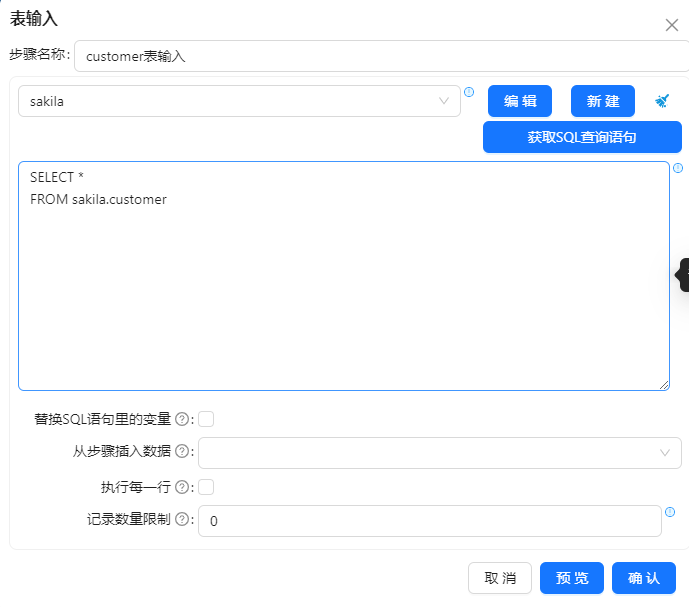

4、将“合并记录”拖至画布,把“customer表输入”和“customer2表输入”步骤都连接到“合并记录”步骤。双击组件来选择哪个步骤是旧数据来源,哪个步骤是新数据来源,选择标志字段,另外设置关键字段和需要比较的字段。配置如下图所示:

5、为了过滤没有发生变化的数据,需要在后面再增加一个过滤步骤。将“过滤记录”和两个“空操作(什么也不做)”组件拖至画布,将“过滤记录”分别连接到两个空操作。双击”过滤记录”组件,设置过滤条件为“flagfield=identical”,值是 “String” 类型,我们把所有没有变化的数据都发送到“空操作(什么也不做)”步骤,把新增、删除、修改的数据发送到“空操作(什么也不做)1”步骤,根据操作对目标表进行更新。“过滤记录”配置如下图所示:
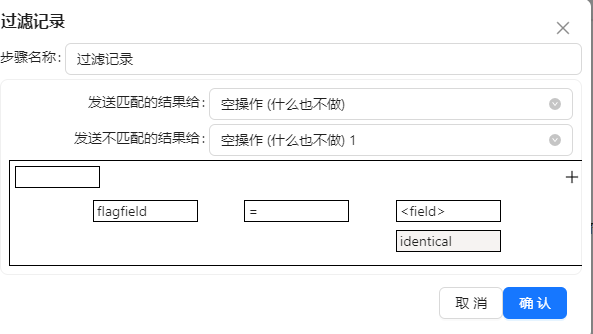
7、完整转换如下图所示:
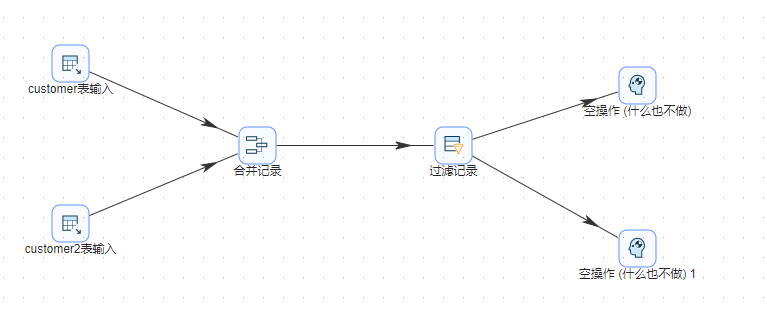
2 点击画布左上角“”按钮运行转换,并在弹出的提示框中点击“启动”按钮,即可运行整个转换。结果如下图所示:
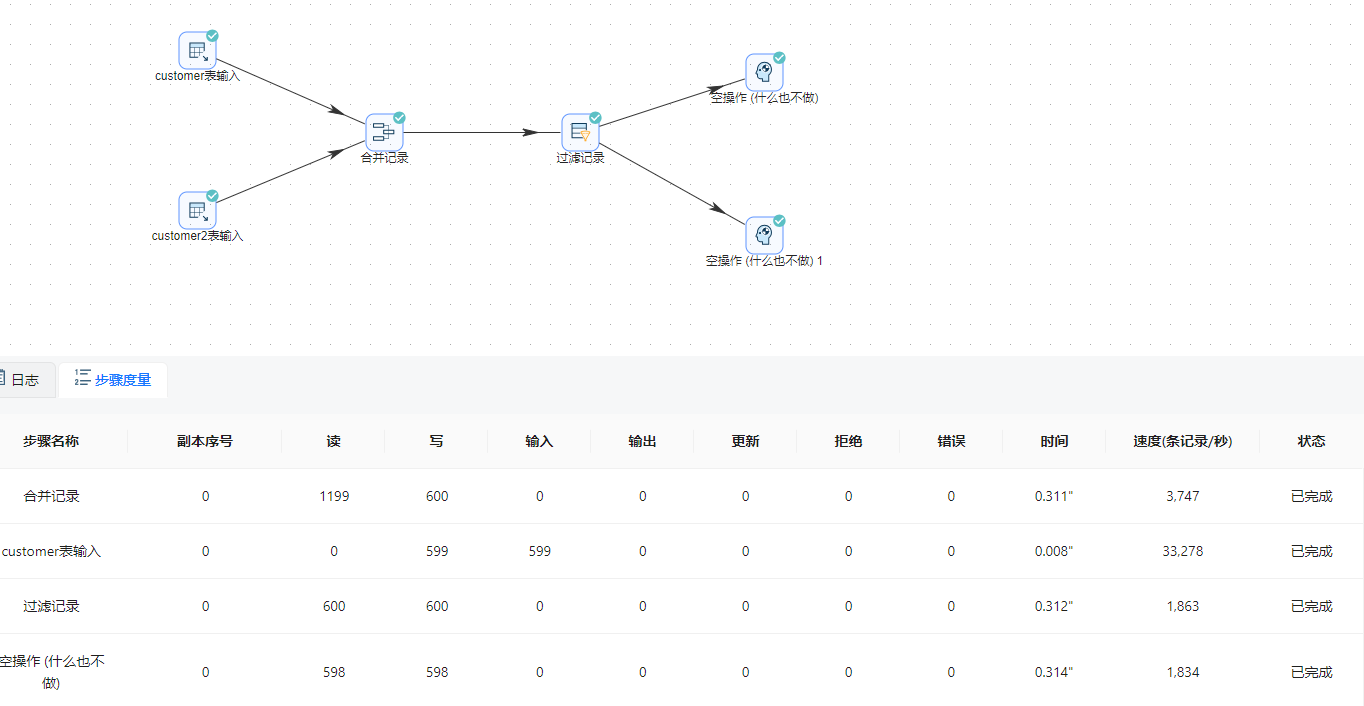
9、选中“空操作(什么也不做)”组件,右击并选中“预览”,可以查看两个表中的变化数据,一条是被更改了【last_name】字段的数据,一条是模拟旧数据被删除的情况。结果如下图所示:

从本小节的例子中可以看出,基于快照的 CDC 可以检测到插入、更新和删除的数据,这是相对�于基于时间戳的 CDC 方案的优点,但它的缺点是要大量的存储空间来保存这些快照。另外,在表比较大时,也会有比较严重的性能问题。因为会有这种性能问题,所以我们前面演示了如何使用 SQL 来做比较,数据库引擎的性能往往比 ETL 引擎的性能更好。之后还会介绍使用 Uniplore 在Data Vault模型下做CDC的例子(2.8Data Vault 管理案例)。