模糊匹配
组件介绍
组件作用
模糊匹配组件使用重复检测算法来查找可能匹配的字符串,该算法计算两个数据流的相似性。 此步骤将匹配值作为由用户定义的最小值或最大值指定的单独列表返回。
输入输出描述
- 输入:数据信息(表,数据库,文件等)输入内容
- 输出:匹配查询成绩输出数据信息
组件图标
页面介绍
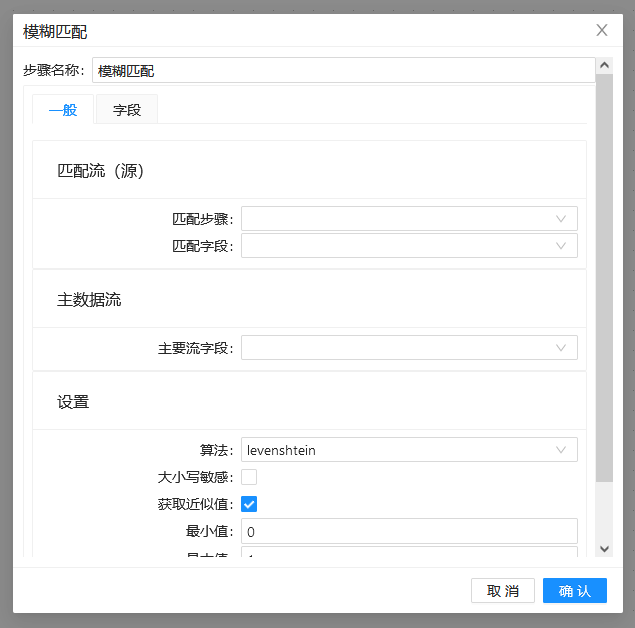
双击模糊匹配组件得到下图所示的界面:
参数选项
模糊匹配组件页面包含如下选项:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 步骤名称 | 步骤的唯一名称,可以自定义名称或保留默认名称 | 模糊匹配 |
| 匹配步骤 | 进行匹配的上一步组件信息 | |
| 匹配字段 | 上一步组件匹配的字段信息 | |
| 主数据流 | 设置匹配数据的来源 | |
| 算法 | 标识要使用的字符串匹配算法-选项包括Levenshtein,Damerau-Levenshtein,Needleman Wunsch,Jaro,Jaro Winkler,成对字母相似度,Metaphone,Double Metaphone,SoundEx或Refined SoundEx | |
| 大小写敏感 | 根据使用大写和小写字母来确定流是否可以不同-仅适用于Levenshtein算法 | |
| 获取近似值 | 选中后,将返回具有最高相似度得分的单个结果,未选中时,将满足最小和最大值设置的所有匹配项作为单独的列表返回,并用值分隔符分隔; | |
| 最小值 | 确定最低的相似度得分 | |
| 最大值 | 确定最大的相似度得分 | |
| 值分隔符 | 标识分隔匹配项的字符串。 仅适用于特定算法,并且未选中“获取更接近的值”选项 | |
| 匹配字段 | 定义包含比较值的列的名称 | |
| 值字段 | 定义要为其返回值的相似性分数 | |
| 返回的�字段 | 输出的字段信息 |
案例示例
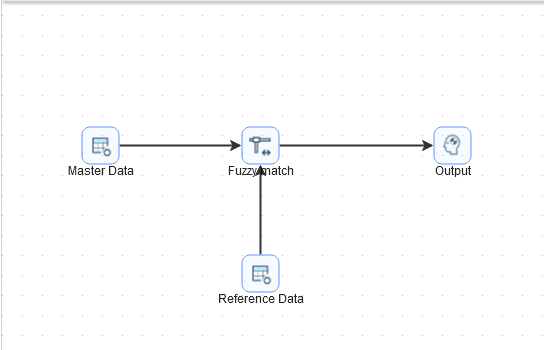
该案例用于计算数据之间的相似度,总体流程如下图所示:
案例操作
该案例利用【模糊匹配】组件计算【自定义常量数据】组件定义的数据的相似度。
自定义常量数据详情请见 自定义常量数据
该组件配置主要分 3 步:
第一步:拖动两个“自定义常量数据”、一个“模糊匹配”组件和一个“空操作”组件到工作区并连接,如下图所示命名每个组件。
第二步:双击两个“自定义常量数据”组件,分别做以下配置:
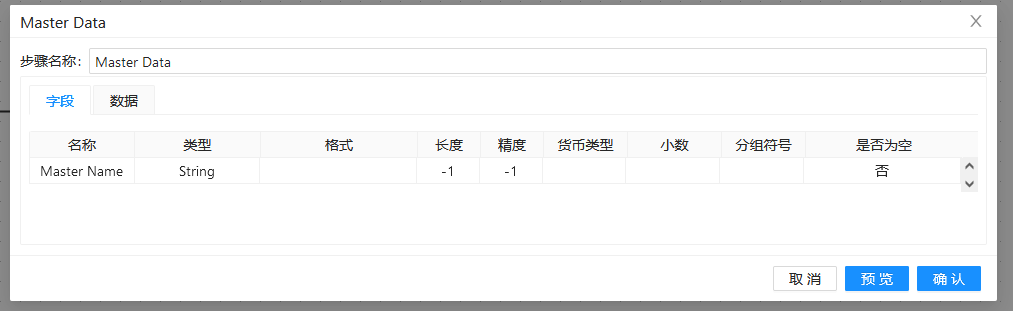
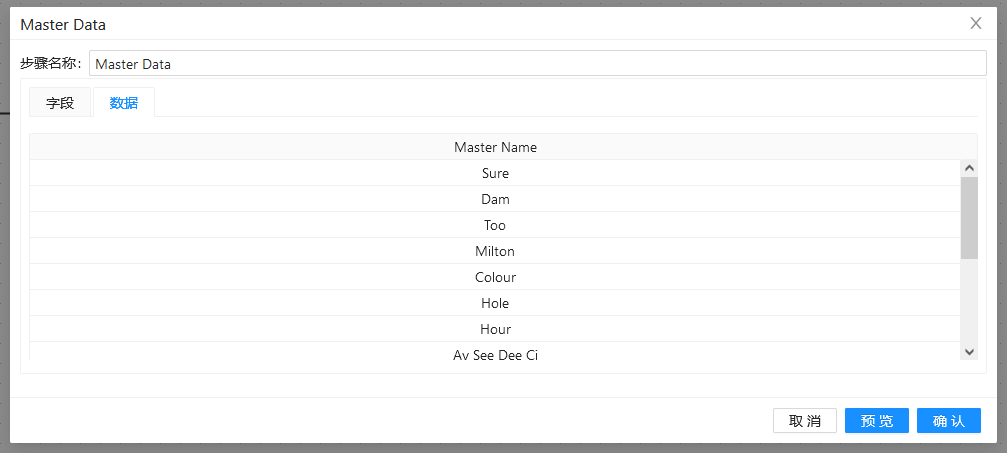
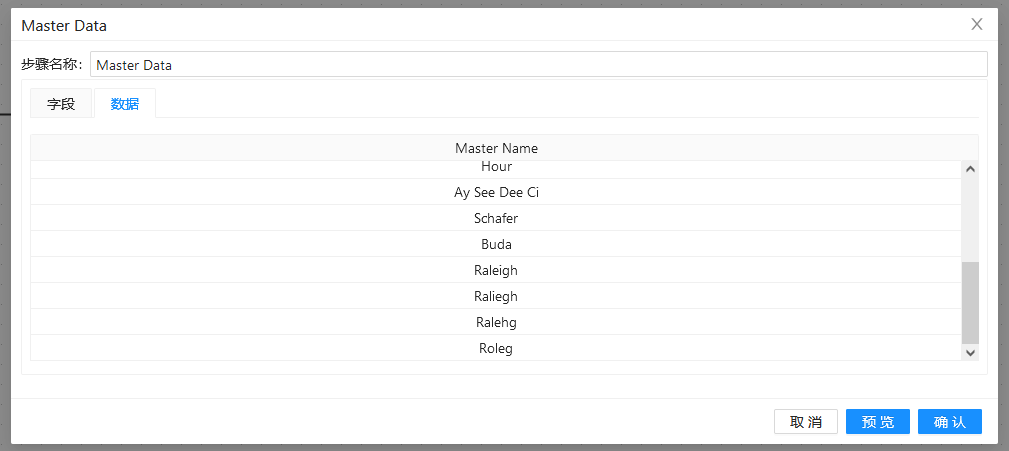
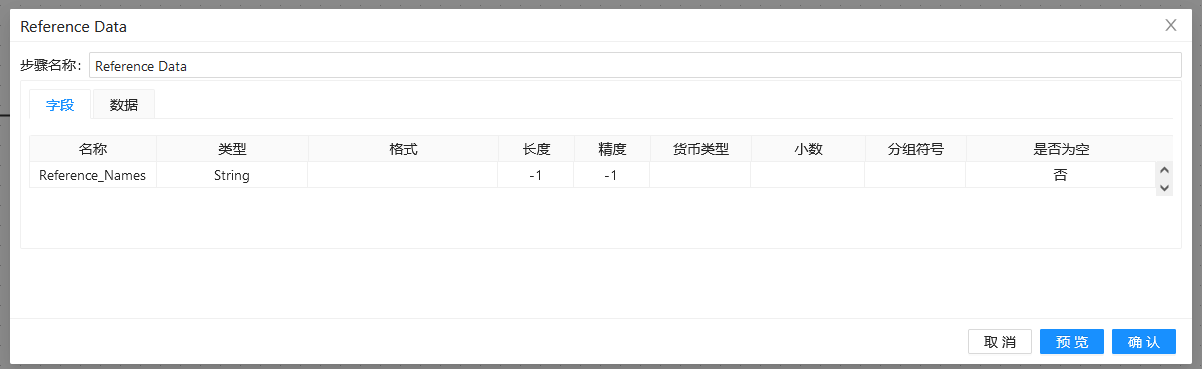
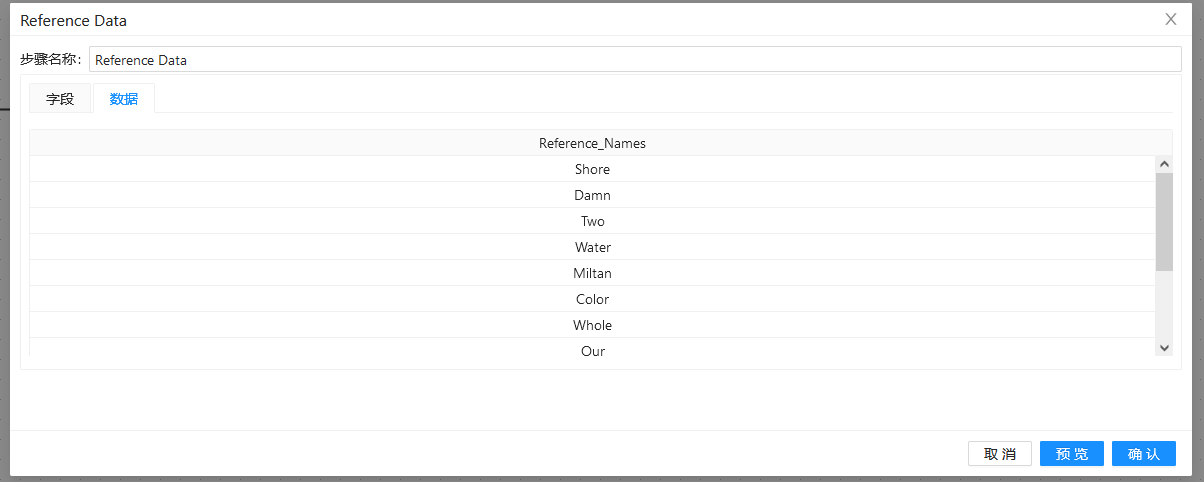
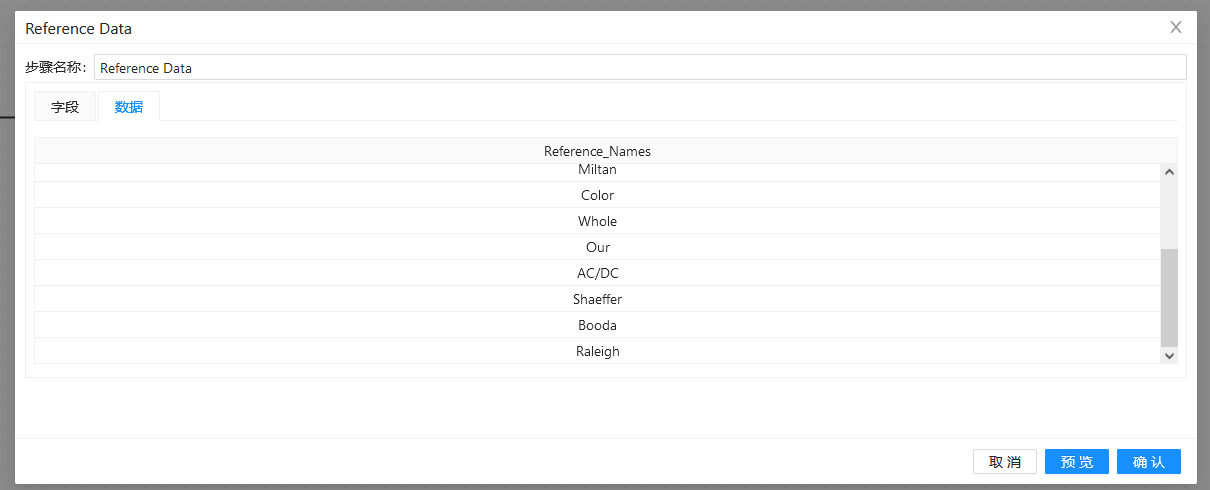
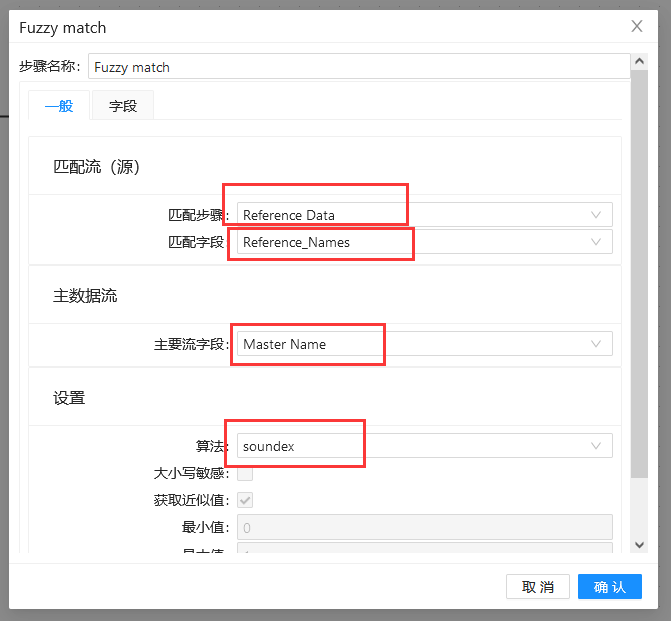
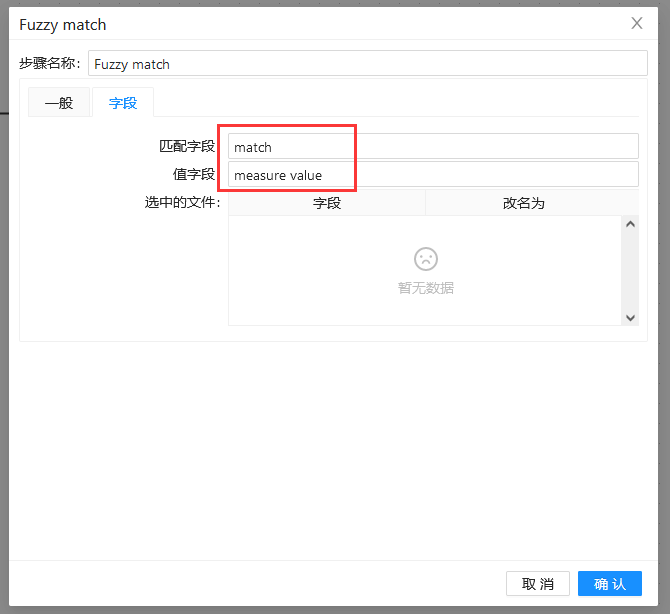
第三步:双击“模糊匹配”组件,填入之前准备好的匹配字段和主要流字段,并使用“soundex”算法:
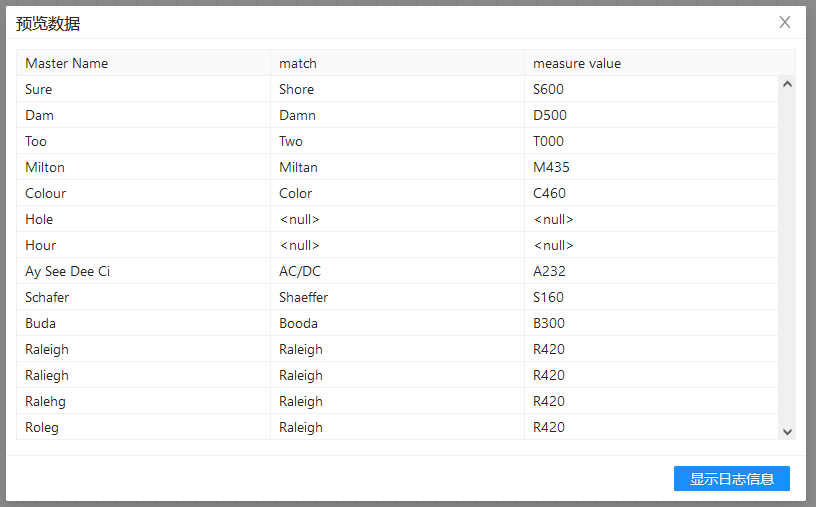
结果预览
"模糊匹配" 组件最终生成数据结果如下图所示: