XGBoost
组件介绍
**“XGBoost”(XGBoost)**控件用于构建XGBoost算法模型。可用于分类任务或回归任务。
XGBoost又叫极度梯度提升树,是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。它在 Gradient Boosting 框架下实现机器学习算法。XGBoost提供并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。
- 输入:
- data:数据集
- pre: 预处理方法
- 输出:
- lrn: 在交互页面中配置参数后的XGBoost学习算法
- mod: 已训练的模型(仅当输入端data存在时,才会有输出信息)
页面介绍
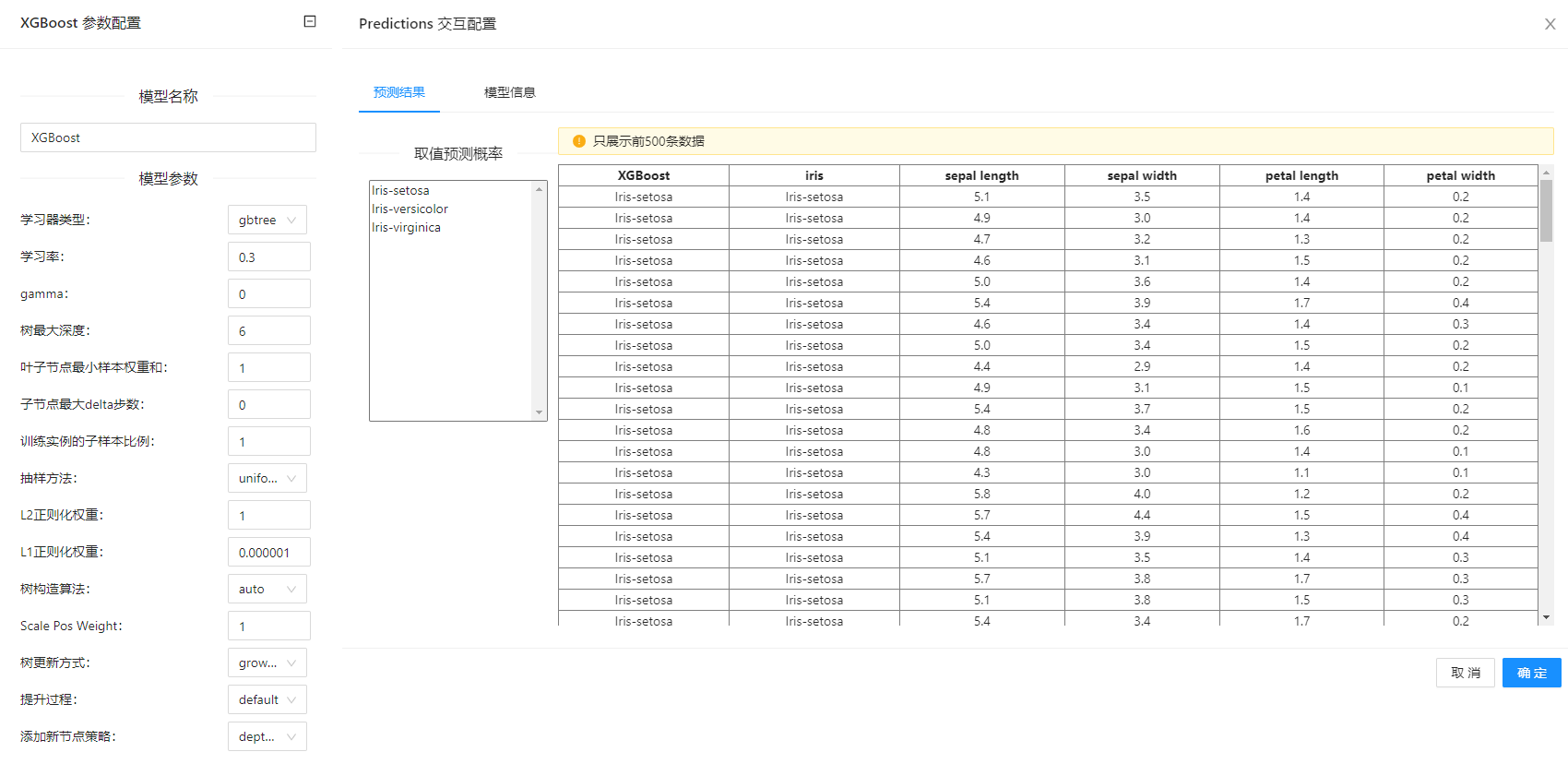
点击**“XGBoost”(XGBoost)**控件查看参数配置页面,如下图所示:
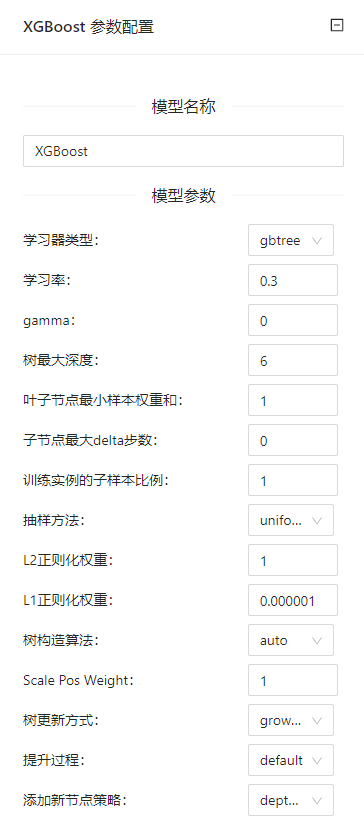
参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| 模型名称 | 设置模型名称,用于在其他组件中区分不同的模型 | 非空字符串 | XGBoost |
| 学习器类型 | 每次迭代时的学习器类型 | gbtree | gbtree |
| 学习率 | 为了防止过拟合,更新过程中用到的收缩步长 | 0.000001~1 | 0.3 |
| gamma | �如果分裂能够使loss函数减小的值大于gamma,则这个节点才分裂。gamma设置了这个减小的最低阈值。如果gamma设置为0,表示只要使得loss函数减少,就分裂 | 0~10000 | 0 |
| 树最大深度 | 树的最大深度 | 0~10000 | 6 |
| 叶子节点最小样本权重和 | 所需观察的叶子节点最小权重总和 | 0~10000 | 1 |
| 子节点最大delta步数 | 在最大增量步长中,允许的每棵树的权重估计。如果该值设置为0,则表示没有约束。如果将其设置为正值,则可以帮助使更新步骤更加保守 | 0~10000 | 0 |
| 训练实例的子样本比例 | 用于训练模型的子样本占整个样本集合的比例 | 0.000001~1 | 1 |
| 抽样方法 | 训练样本的采样方法 | uniform | uniform |
| L2正则化权重 | 关于权重的L2正则项(类似于岭回归) | 0.000001~1 | 1 |
| L1正则化权重 | L1正则化项的权重(类似于Lasso回归) | 0.000001~1 | 0.000001 |
| 树构造算法 | 树构造算法 | auto | auto |
| Scale Pos Weight | 在高级别不平衡的情况下,应使用大于0的值,因为它有助于更快的收敛。 | 0.000001~1 | 1 |
| 树更新方式 | 定义了要运行的树更新�器的顺序,提供构建和修改树的模块化方法 | grow_colmaker | grow_colmaker |
| 提升过程 | 运行提升过程的一种类型 | default | default |
| 添加新节点策略 | 控制增加新节点的方式 | depthwise | depthwise |
使用案例
在下图所示的案例中,使用**“加载文件”(File)控件加载数据集,连接“XGBoost”(XGBoost)控件进行模型构建,之后把“加载文件”(File)控件以及“XGBoost”(XGBoost)控件与“预测”(Predictions)**控件连接起来查看预测的结果。
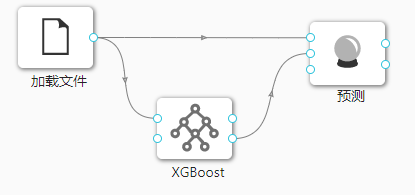
案例中加载 iris 数据集,其余参数使用默认值。案例中控件的配置以及执行结果如下图所示。