自动特征工程
组件介绍
“自动特征工程”(Feature Synthesis) 控件自动为关系数据集生成特征。
“自动特征工程”(Feature Synthesis) 控件将数据中的关系跟踪到基本字段,然后沿该路径顺序应用数学函数以创�建最终特征。通过顺序地堆叠计算,我们观察到我们可以将每个新特征定义为具有一定深度。
- 输入:
- data:数据集
- 输出:
- data:经过深度特征综合后的数据集
页面介绍
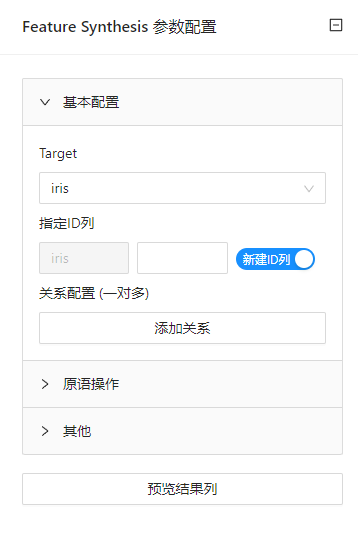
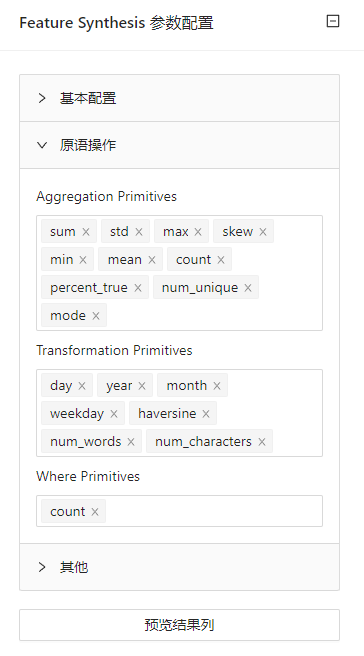
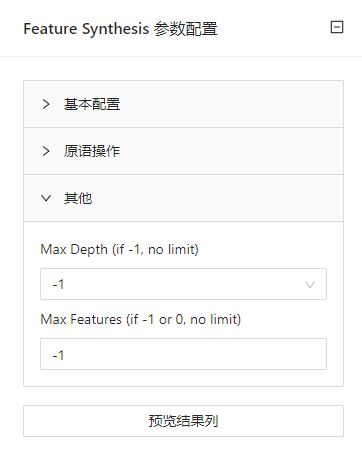
点击 “自动特征工程”(Feature Synthesis) 控件查看参数配置页面,如下图所示:
获取属性信息的逻辑如下:
- 优先解析直接上游组件的输出结果,需要您先将上游组件运行成功
- 如1不满足,将会追溯源头的File、SQL Table等加载数据的属性信息
若属性信息获取错误,可通过重置控件重新获取。
参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| Target | 添加实体 | 数据集中的目标属性 | iris |
| ID Relations [a one-to-many relationship] | 在实体集合中添加表关系(一对多关系) | 多个数据集间的关系 | |
| Aggregation Primitives | 聚合原语,这些原语将相关实例作为输入并输出单个值。它们适用于实体集中的父子关系。如:"count","sum","avg_time_between"。 | num_true | sum, std |
| Transformation Primitives | 转换原语,这些基元将实体中的一个或多个变量作为输入,并为该实体输出新变量。它们适用于单个实体。如:"hour","time_since_previous","absolute"。 | age | age, hour |
| Filtering ValuesWhere Primitives | 根据聚合原语或转换原语过滤值 | 聚合原语与转换原语的并集 | sum, hour |
| Max Depth [If -1, no limit] | 控制DFS返回的要素的最大深度 | -1 | -1 |
| Max Features [If -1 or 0, no limit] | 最大特征量 | -1~10000 | -1 |
使用案例
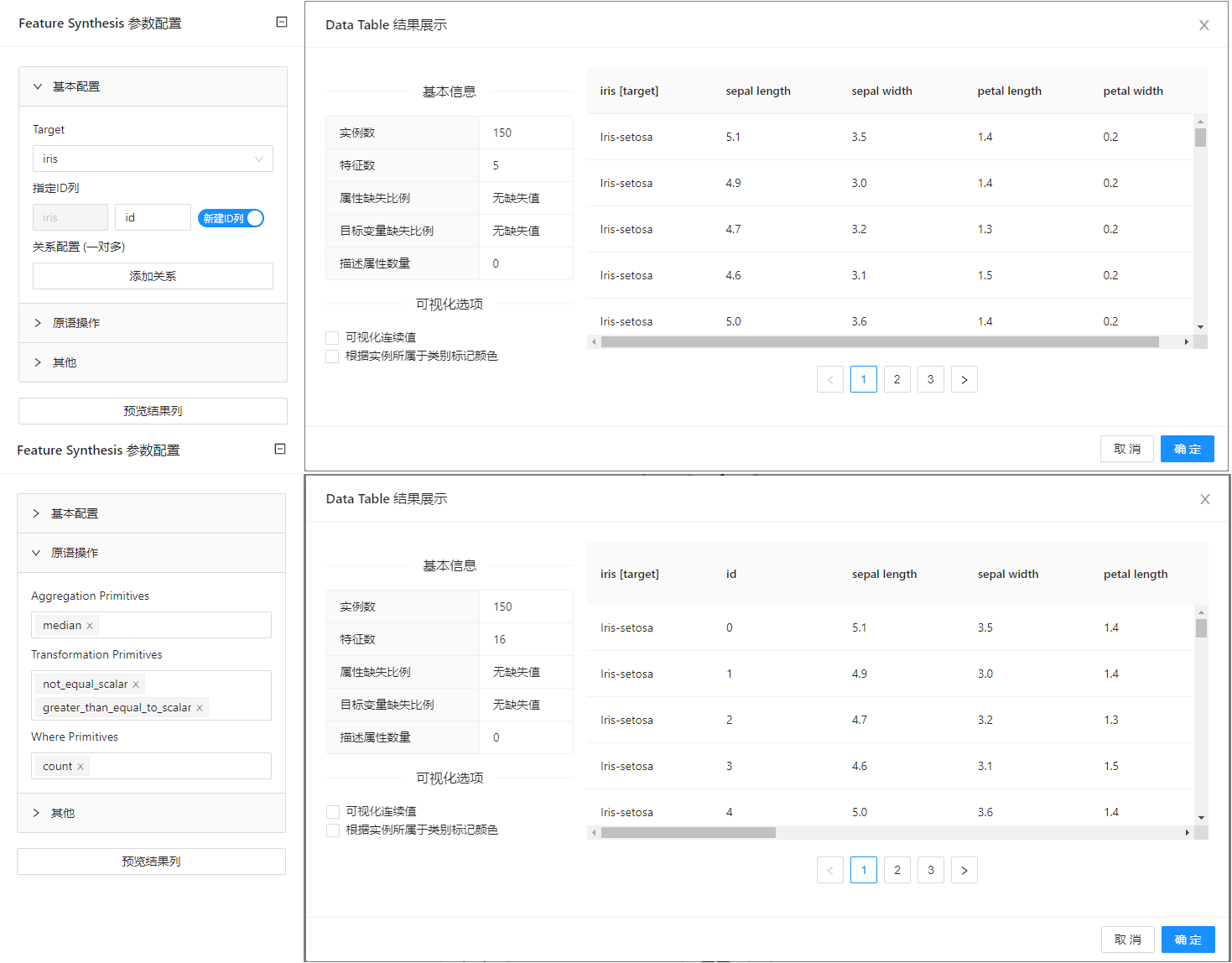
在下图所示的案例中,使用 “加载文件”(File) 控件加载数据,通过 “查看数据”(Data Table) 控件查看加载数据的信息,同时使用 “自动特征工程”(Feature Synthesis) 控件进行数据处理,之后通过 “查看数据”(Data Table) 控件查看处理后的数据集。
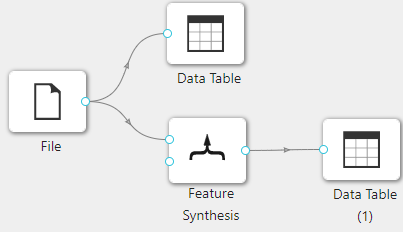
案例中加载 iris 数据集, “自动特征工程”(Feature Synthesis) 控件中指定ID列名为id,Aggreagtion Primitives选择median,Transformation Primitives选择not_equal_scalar和greater_than_equal_to_scalar,其余使用默认参数。案例中控件的配置以及执行结果如下图所示。