Partition Schema
功能介绍
分区功能是根据某个字段的值对数据进行分组后并发执行工作流,一种通俗的理解,在UDI Studio的工作流(pipeline)中设置partition schema的组件(Transform),实际执行的时候,会将该组件复制出"分区数"相同的组件数量来执行。我们可以利用此功能进行并行将同样的数据写入多种数据库分区等工作。如下图所示,
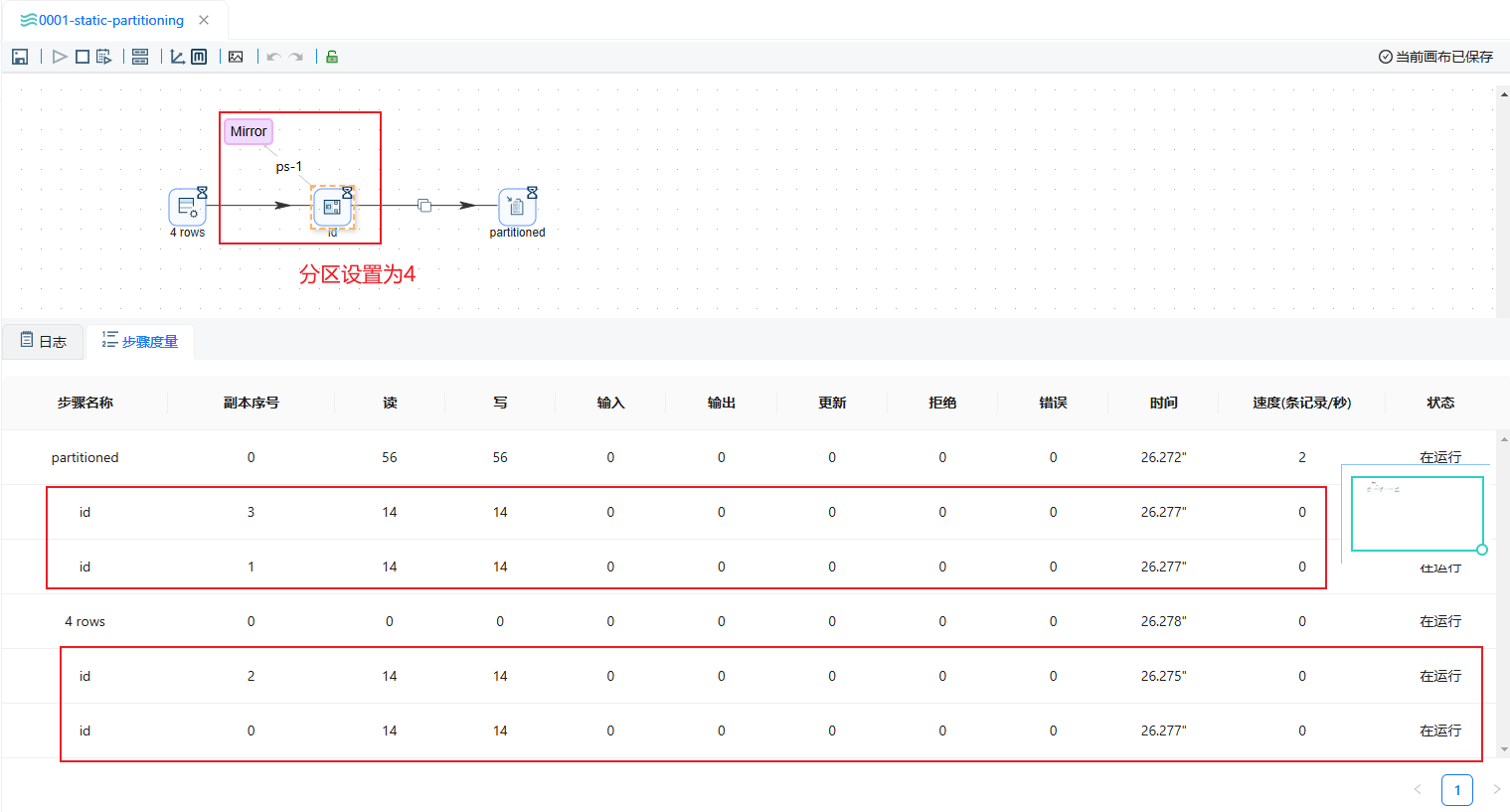
上图的工作流当中,我们对名为id的组件设置分区数为4,在实际运行中,有4个关于id组件的进程在运行。
页面介绍
| 列名 | 说明 | 样例值 |
|---|---|---|
| Partition Schema 名称 | 分区模式的名称,不可重复 | partition-schema-1 |
| 动态创建Schema定义 | 1.当选用动态创建Schema定义,实际分区数以下面分区数为准. 2.当禁用动态创建Schema定义,实际分区以自定义的分区列表个数为准 | |
| 分区数 | 分区的数量 | 4 |
| 分区 | 分区 ID 列表 |
Partition Schema的基本操作
新建Partition Schema
用户可以在元数据管理中新增 Partition Schema,该功能分为3步:
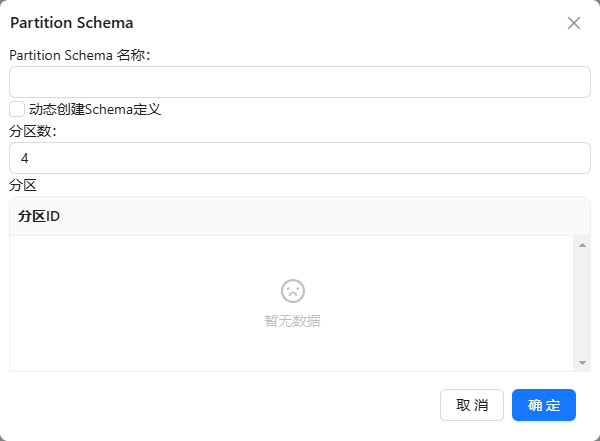
- 第一步:在元数据下找到“Partition Schema”,右键选择新增,如下图所示:

- 第二步:弹出如下图所示的页面:
- 第三步:根据需要使用正确的配置Partition Schema保存即可
修改Partition Schema
用户可以在元数据管理中编辑 Partition Schema,该功能分为3步:
- 第一步:在元数据下找到“Partition Schema”,展开“Partition Schema”,在需要编辑的Partition Schema右键选择编辑,如下图所示:
- 第二步:弹出如下图所示的页面:
- 第三步:根据需要编辑正确的配置Partition Schema保存即可
删除Partition Schema
用户可以在元数据管理中删除Partition Schema,该功能分为3步:
- 第一步:在元数据下找到“Partition Schema”,,展开“Partition Schema”,在需要编辑的Partition Schema右键选择删除,如下图所示:
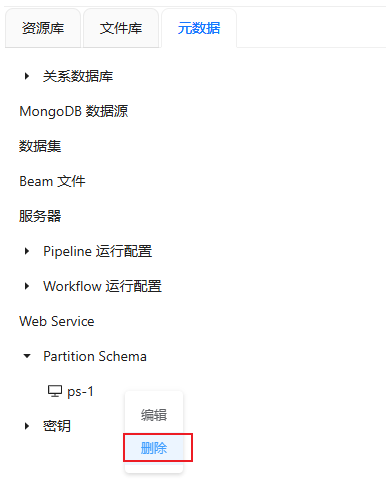
- 第二步:弹出如下图所示的页面:

- 第三步:点击确定后删除选中的Partition Schema
使用案例
本案例演示如何使用Partition Schema功能将 一张数据库表 的数据分发到 两张数据库表
Mod 模式分区
1、新建分区

Tip:上面的"分区ID", 在组件中可以通过${Internal.Transform.Partition.ID}变量引用获取
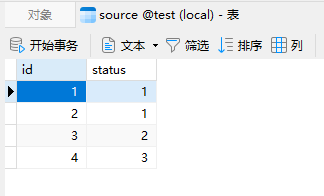
2、新建数据
source表中的数据:
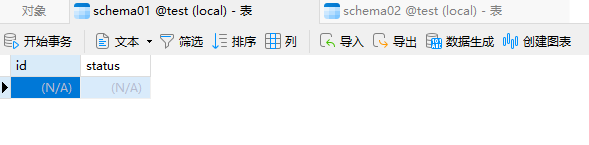
schema01和schema02表中均无数据
3、新建工作流
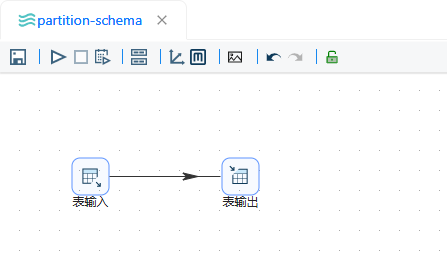
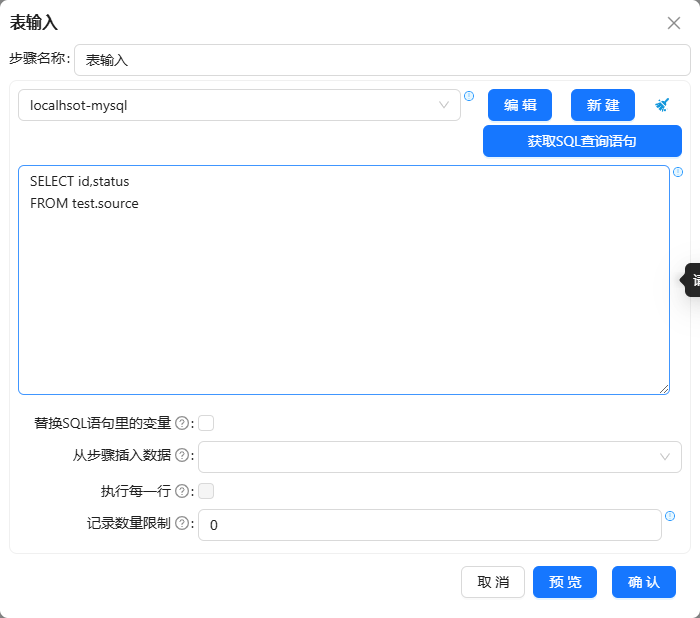
表输入组件配置如下所示:
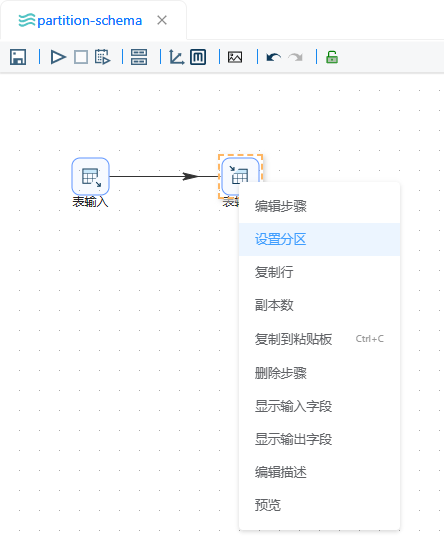
在表输出组件上右键点击“设置分区”
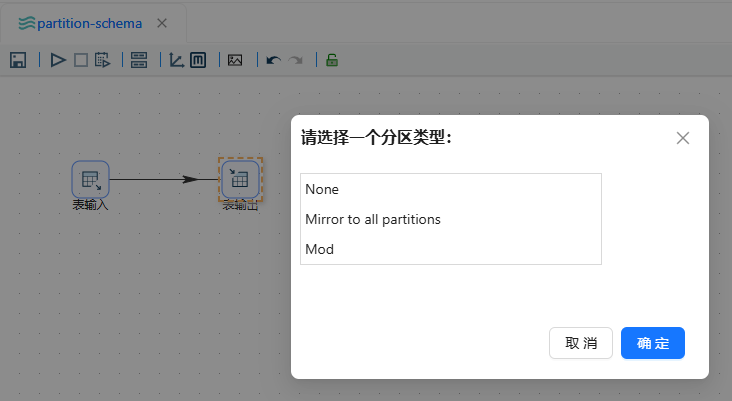
后出现分区类型
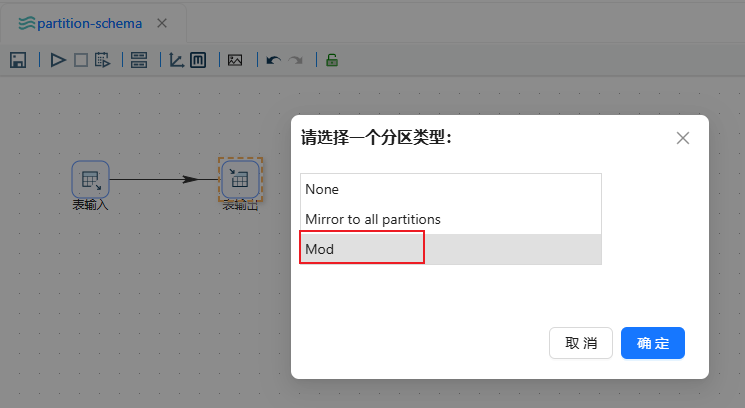
这里先选择 Mod 按照分区字段取余数进行分区入库
再选择刚刚新建的分区
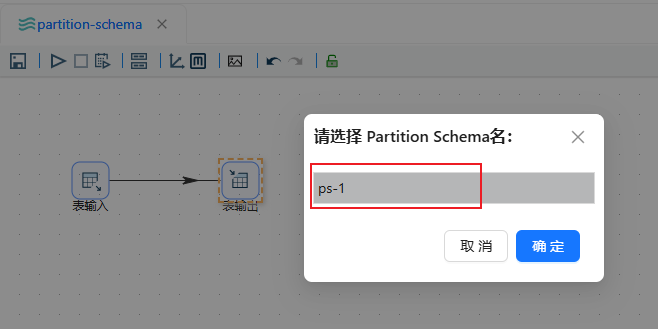
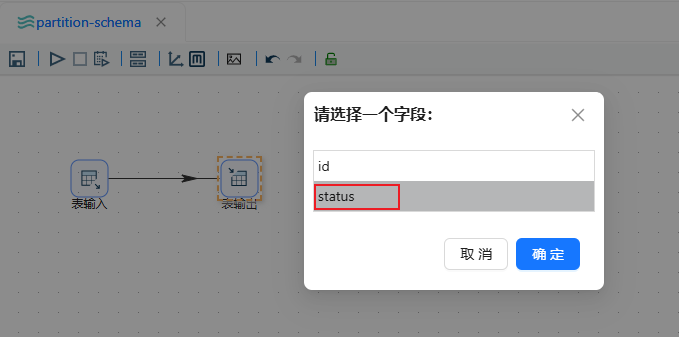
再选择以那个字段进行分区,这里选择"status",点击确定
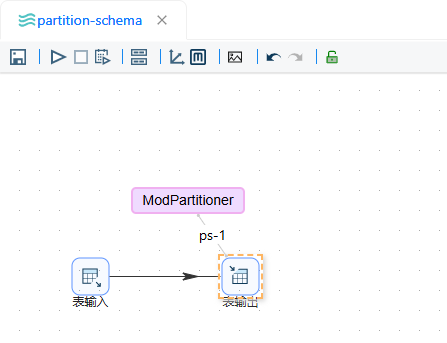
添加分区后工作流如下:
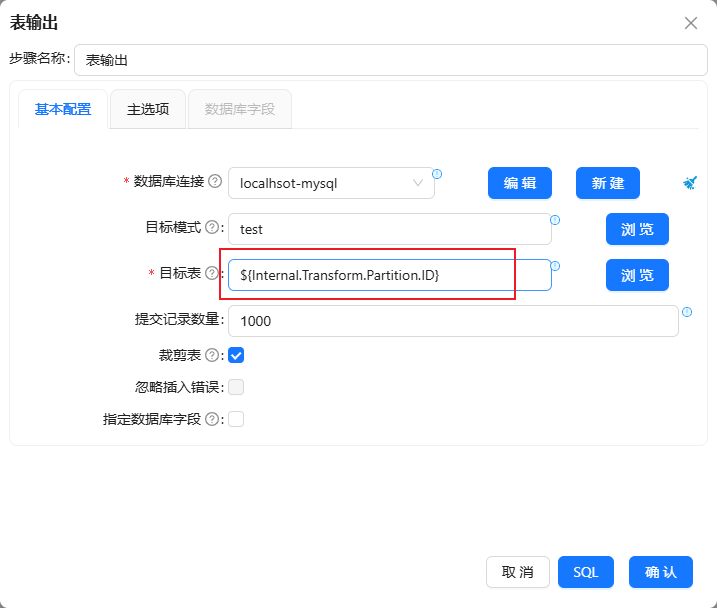
然后打开表输出组件的编辑页面,设置目标表为“${Internal.Transform.Partition.ID}”
4、运行工作流
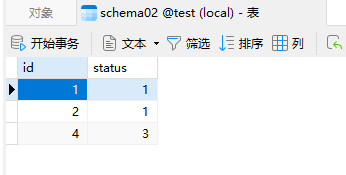
运行工作流后查看 schema01 和 schema02 表中的数据库,可以看到source表中的数据根据status字段分区后,分别保存到数据库中,保存的原理是,使用所选字段的值取余数进行分类,例如:如果status等于1,分区数为2,那么1%2=1 ,保存在schema02表,如果status等于2,那么2%2=0,保存在schema01,如果status等于3,那么3%2=1,保存在schema02表, 如下图所示

Mirror to all partitions 模式分区
1、设置分区模式
前面的操作同上,在表输出组件上右键点击“设置分区”,选择 Mirror to all partitions 分区模式
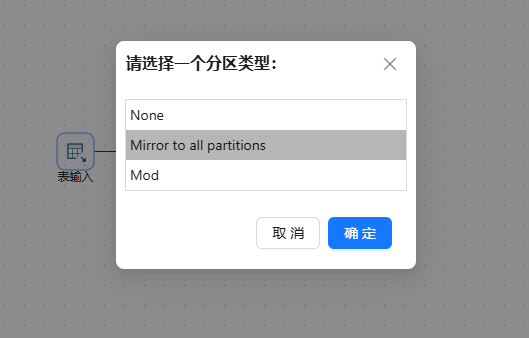
再选择刚刚新建的分区,点击确定后该模式不需要选择字段
2、运行工作流
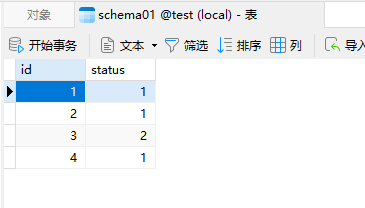
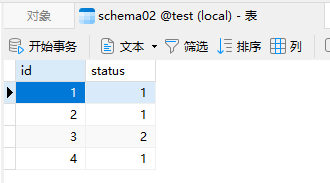
运行工作流后查看schema01和schema02表中的数据库,可以看到test表中的数据全部保存到2个数据库中,如下图所示
None 分区模式
None分区模式就是取消设置分区,不再使用分区功能
分区模式总结
- Mod模式会指定一个字段进行分区,该模式会把不同分区的数据保存到不同数据库表中
- Mirror to all partitions模式无需指定字段,该模式会把所有的数据都保存到所有的数据库表中
- None模式即会取消使用分区功能