pipeline 运行配置
页面介绍

| 列名 | 说明 | 样例值 |
|---|---|---|
| 姓名 | 用于此pipeline运行配置的名称 | |
| 描述 | 用于此pipeline运行配置的描述 | |
| 引擎类型 | 用于此pipeline运行配置的引擎类型。 |
引擎类型介绍
Beam Flink 引擎
Apache Flink 是一个批流一体化的分布式大数据处理引擎,其非常适用于处理大规模、连续作业,同时提供:
- 批量数据处理和流式数据处理
- 同时支持极高吞吐量和低事件延迟
- 具有一次性处理保证的容错能力
- 流式数据处理的自然背压
- 自定义内存管理,可在内存和核外数据处理算法之间进行高效、稳健的切换
- 与 YARN 和 Apache Hadoop 生态系统的其他组件集成
Beam Flink pipeline执行引擎可以将您在UDI Studio编辑好的pipeline放到Apache Flink(版本:Apache Flink 1.16.2及以上)上面去执行。
Apache Flink 的安装
-
进入Apache Flink 官网下载页面,选择相应的版本进行下载(推荐下载 1.16.2 版本);
-
将压缩包上传至服务器并解压;
-
进入到Apache Flink 解压后的文件夹;
-
Apache Flink 1.15.x 版本以上需要修改一直配置才能远程访问 Flink Web UI:
cd conf进入 Apache Flink 的配置文件目录;- 找到里面的flink-conf.yaml文件并编辑;
- 作如下修改:
rest.address 设置为 0.0.0.0
rest.bind-address 设置为0.0.0.0
- 保存后退出,回到Apache Flink 文件夹内部.
-
cd bin进入Apache Flink 的存放命令的文件目录 -
./start-cluster.sh命令启动 Flink.(./stop-cluster.sh可以停止运行Flink) -
此时浏览器打开 服务器IP:8081 就可以访问Flink Web UI,如下图:
Beam Flink 引擎配置
新建pipeline运行配置时,引擎类型选择【Beam Flink 引擎】即可配置Beam Flink引擎的相关配置
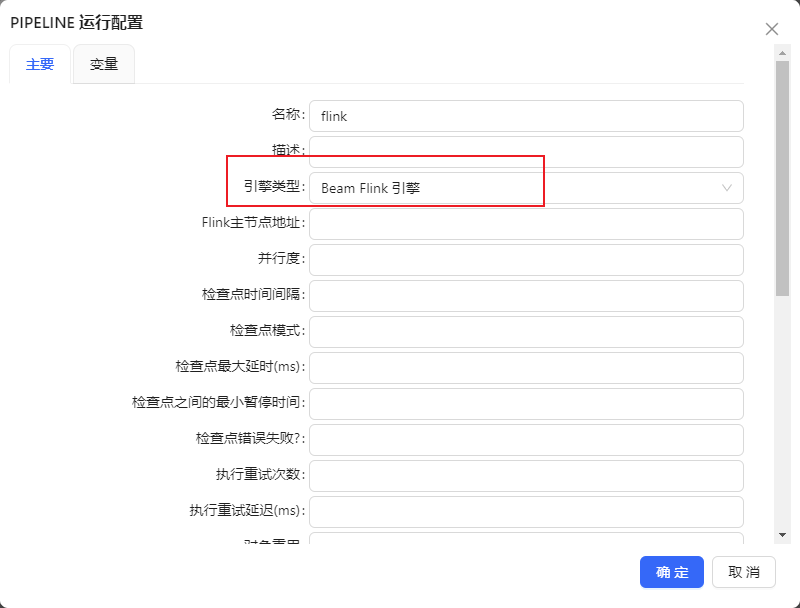
每个配置项的作用如下表
| 配置名 | 说明 | 样例值 |
|---|---|---|
| Flink主节点地址 | 执行Pipeline的Flink主节点的地址,"host:port"形式 | 192.168.103.64:8081 |
| 并行度 | pipeline最大并行度,最大并行度规定了动态扩展的上限和用于分区状态的关键组数量 | 4(可不填,默认-1) |
| 检查点时间间隔 | 运行pipeline检查点的时间间隔,单位毫秒 | 5(可不填,默认-1) |
| 检查点模式 | 设置Flink检查点模式:Exactly-once、At-least-once、None | Exactly-once (可不填,默认None) |
| 检查点最大延时(ms) | 检查点在被丢弃之前允许的最大时间 | 5(可不填,默认-1) |
| 检查点之间的最小暂停时间 | 触发下一个检查点前的最小停顿时间(毫秒) | 5(可不填,默认-1) |
| 检查点错误失败? | 设置任务在检查点程序中遇到错误时的预期行为。如果设置为 true,任务将在检查点错误时失败。如果设置为 false,任务只会拒绝检查点并继续运行 | false(可不填,默认true) |
| 执行重试次数 | 执行失败尝试重新执行的次数 | 2(可不填,默认-1) |
| 执行重试延迟(ms) | 设置执行之间的延迟时间 | 2(可不填,默认-1) |
| 对象重用 | 设置重用对象的行为。启用对象重用模式将指示运行时重用用户对象,以提高性能。 | true(可不填,默认false) |
| 禁用指标 | 禁用 Beam 指标 | (可不填,默认-1) |
| 禁用外部化检查点 | 不使用外部的检查点 | (可不填,默认true) |
| 取消时保留外部化检查点 | 设置取消时外部化检查点的行为 | true(可不填,默认false) |
| 最大捆绑大小 | 捆绑包中元素的最大数量 | 5(可不填,默认1000) |
| 最大捆绑时间(毫秒) | 完成捆绑之前等待的最长时间(以毫秒为单位) | 5(可不填,默认1000) |
| 关闭最终水印上的源 | 关闭已闲置达配置毫秒的源。源一旦关闭,就无法再进行检查点处理。一旦处理完所有输入,关闭源最终会导致管道关闭(=Flink 作业结束)。除非明确设置,否则��在启用检查点功能时,该值默认为 Long.MAX_VALUE,而在禁用检查点功能时,该值默认为 0。 | |
| 延迟跟踪间隔 | 以毫秒为单位的时间间隔,用于从源向汇发送延迟跟踪标记。 | |
| 自动水位线时间间隔 | 自动发射水印的时间间隔(毫秒) | |
| 用户代理 | 描述外部服务管道的用户代理字符串 | user(可不填,默认Hop) |
| 临时目录 | 临时文件的目录地址 | |
| 流式Hop transforms刷新时间间隔(ms) | 内部缓冲区完全通过网络发送并清空的时间 | |
| Hop streaming transforms 缓冲区大小 | 要使用的内部缓冲区大小 |
Beam Direct 引擎
Beam Direct 引擎可用于本地测试和开发,Direct可在您的机器上执行您在UDI Studio上编辑好的pipeline,旨在验证pipeline是否尽可能地遵循 Apache Beam 模型。Direct不仅关注pipeline的高效执行,还会执行额外的检查,以确保用户不会依赖于模型无法保证的语义。
使用Beam Direct 引擎进行测试和开发,有助于确保pipeline在Beam Flink上运行也能保持稳定。此外,当pipeline在远程集群上执行时,调试失败的运行可能是一项非同小可的任务。相反,对pipeline代码执行本地单元测试通常更快更简单。在本地对pipeline进行单元测试,还可以使用自己喜欢的本地调试工具。
当新建pipeline运行配置时选择“Beam Direct 引擎”时,显示如下图:
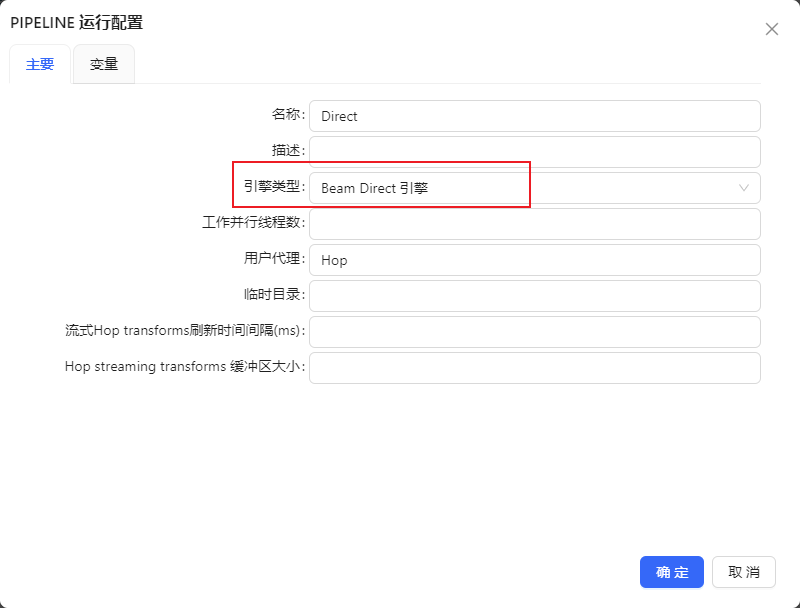
Beam Direct 引擎每个配置项的作用如下表
| 配置名 | 说明 | 样例值 |
|---|---|---|
| 工作并行线程数 | 线程数或子进程数用于配置并行性。设置为 0 时,会将线程/子进程数设置为流水线运行所在机器的内核数 | 1 |
| 用户代理 | 描述外部服务管道的用户代理字符串 | user(可不填,默认Hop) |
| 临时目录 | 临时文件的目录地址 | |
| 流式Hop transforms刷新时间间隔(ms) | 内部缓冲区完全通过网络发送并清空的时间 | |
| Hop streaming transforms 缓冲区大小 | 要使用的内部缓冲区大小 |
本地 pipeline 引擎
可在本地机器上运行您在UDI Studio上编辑好的pipeline,当新建pipeline运行配置时选择“本地pipeline引擎”时,显示如下图:
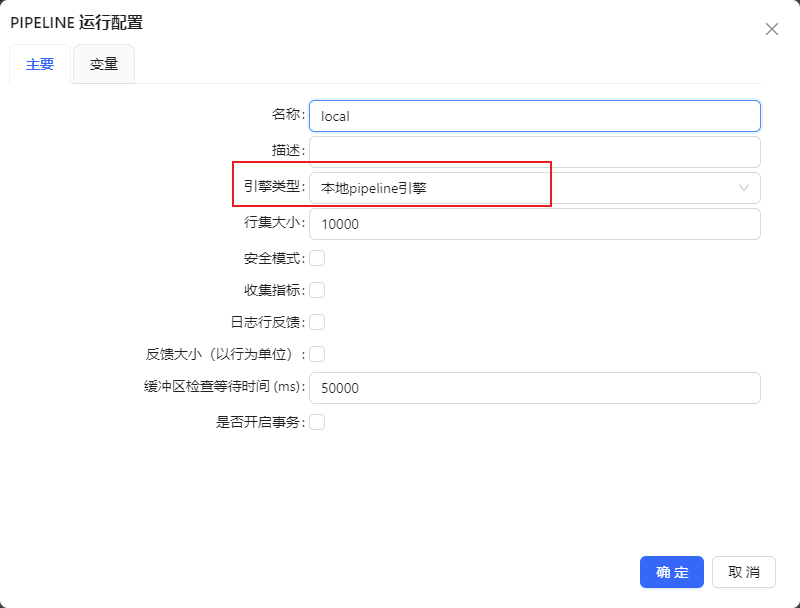
下表是您在本地机器上运行pipeline时使用的运行时配置
| 配置名 | 说明 | 默认值 |
|---|---|---|
| 行集大小 | 行集缓冲区大小 | 1000 |
| 安全模式 | 检查通过pipeline的每一行,确保所有布局相同。如果某一行的布局与第一行不一致,就会生成并报告错误 | false |
| 收集指标 | 收集监测pipeline性能的指标 | false |
| 日志行反馈 | 启用日志行反馈,每处理 50000 行(默认)的倍数后显示一��行日志 | false |
| 反馈大小(以行为单位) | 作为反馈返回的行数 | 50000 |
| 缓冲区检查等待时间 (ms) | 该值表示变换的输入缓冲区中没有行时的轮询频率,当流水线中有很多空闲变换时,该值越低,CPU 负载越高 | 20 |
| 是否开启事务 | 如果启用此功能,每个数据库将始终只使用一个连接。在管道结束时,所有命名的连接将同时提交或回滚(出错时)。请注意,子管道或工作流也会自动作为事务运行。还要注意的是,虽然可以跨多个数据库提交和回滚,但这仍然意味着可能会出现在一个数据库提交成功而在另一个数据库提交失败的情况。这不是一个两阶段提交系统 | false |
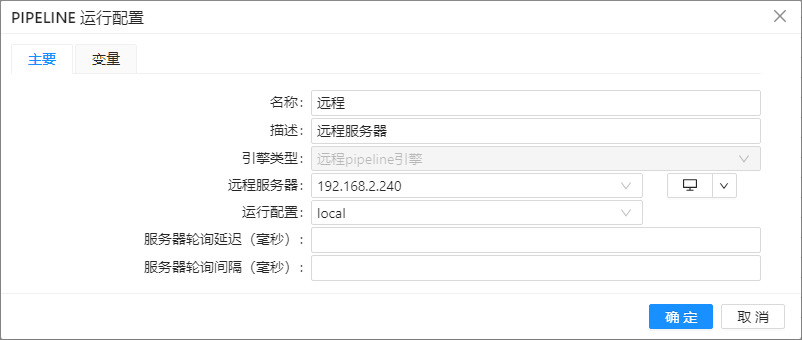
远程 pipeline 引擎
当新建pipeline运行配置时选择“远程 pipeline 引擎”时,显示如下图:

| 列名 | 说明 | 样例值 |
|---|---|---|
| 远程服务器 | 选择需要执行的远程服务器 Hop Server | |
| 运行配置 | 选择远程服务器执行时使用的运行配置 | |
| 服务器轮询延迟(毫秒) | 定期轮询远程服务器之间的延迟。 | 1000 毫秒 |
| 服务器轮询间隔(毫秒) | 定期轮询远程服务器之间的时间间隔。 | 2000 毫秒 |
pipeline 运行配置的基本操作
新建 pipeline 运行配置
用户可以在元数据管理中新增 pipeline 运行配置,该功能分为3步:
- 第一步:在元数据下找到“pipeline 运行配置”,右键选择新增,如下图所示:

第二步:弹出如下图所示的页面:
- 第三步:根据需要使用正确的配置pipeline运行配置保存即可
修改 pipeline 运行配置
用户可以在元数据管理中编辑 pipeline 运行配置,该功能分为3步:
- 第一步:在元数据下找到“pipeline 运行配置”,展开“pipeline 运行配置”,在需要编辑的pipeline 运行配置右键选择编辑,如下图所示:

第二步:弹出如下图所示的页面:
- 第三步:根据需要编辑正确的配置pipeline运行配置保存即可
删除 pipeline 运行配置
用户可以在元数据管理中新增pipeline 运行配置,该功能分为3步:
- 第一步:在元数据下找到“pipeline 运行配置”,,展开“pipeline 运行配置”,在需要编辑的pipeline 运行配置右键选择删除,如下图所示:

第二步:弹出如下图所示的页面:

- 第三步:点击确定后删除选中的pipeline运行配置
pipeline 运行配置的使用
pipeline 运行配置在pipeline运行时使用,用来说明该工作流文件使用那个引擎来运行,如下图:
