数据去重
案例说明
数据排重是一项具有挑战性的工作,很多客户表里都有重复数据,例如 CRM(Customer Relationship Management)系统里,这个系统里的很多数据是呼叫中心的客服代表录入的。客服代表没有足够的时间检查一个打电话过来的客户是否在系统中已经存在,或者错误拼写了名字或地址,并保存到了数据库中。以后在使用这些数据时,如给客户发促销邮件,就会发生问题。所以,很多 CRM 系统初始化时,都要清洗客户数据,保证数据库里一个客户只有一条记录。当然,问题是如何检测出重复的数据?更具有挑战性的是:如何在没有主键的情况下或主键可能拼写错误的情况下,检测到重复数据。遗憾的是,对这类问题,不会有任何一个软件或方法可以百分之百解决。但通过模糊匹配,可以逐渐把数据整理好。
完全重复问题
UDI 有去除重复记录的组件,去除重复记录组件只能识别完全相同的数据行,而且检查可以只限制在某几个字段。例如,一个公司想给每个客户地址寄送直邮广告,输入数据需要有客户号和地址信息,而且地址信息需要排序,前提是例子里至少要有两个相同地址的客户信息。接下来将介绍如何用 Uniplore 完成这个例子,具体操作如下:
(1) 新建转换,将csv 文件输入组件拖至画布,双击组件,获取需要的客户号和地址信息并按照地址号排序,配置如下图所示:
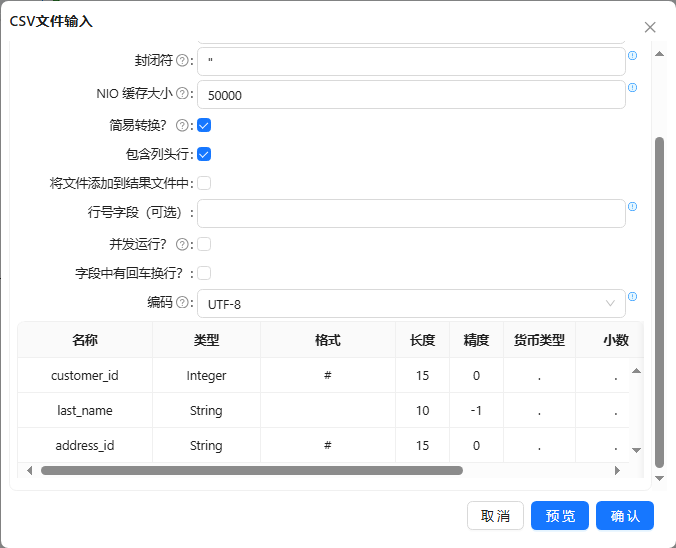
(2) 将去除重复记录拖至画布,去除重复的地址信息,并记录地址号出现的次数;

(3) 再将空操作(什么也不做)组件拖至画布,双击组件,步骤名称改为“UniqueRows”,并将去除重复记录连接这个步骤,若提示选择步骤,依然选择主输出步骤。完整转换如下图所示:

(4) 运行转换,结果如下图所示,可以观察到去除重复记录中读取是 600 行数据,但输出是 599 行数据,说明确实去除了一行重复及录:

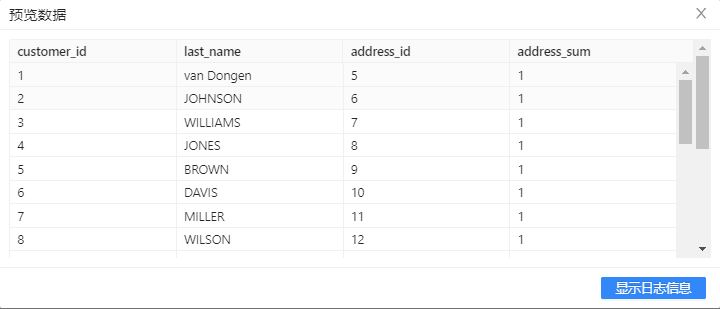
(5) 选中UniqueRows组件,右击并选中预览查看数据。【address_sum】字段显示【address_id】字段出现的次数,此处数据的重复率并不高,但当数据拥有很多重复信息时,计数器将起到重要的作用。结果如下图所示:
不完全重复问题
正如在本案例前面介绍的那样,大多数数据质量问题是由客户和产品数据引起的。下面的例子都聚焦在客户数据上,因为客户数据易于理解,先来看一些典型的客户名称重复的例子。
假设 CRM 系统里存储了客户的姓氏、名字、电子邮件地址、城市和国家,如下图所示:

图中可以简单识别出这两条记录指向同一个人,但随着数据量级的增大,如:3 条、30 条、3亿条,这种重复数据就很难通过人工去查了,这时就需要用到一些算法来识别重复的数据。
一些字段的数据完全相同,另一些字段可能拼写错误或拼写方式不同。使用 SQL 是很难解决这种可能重复数据的问题的:不能使用相等检测,而“like”检查也不可行,因为要事先指定搜索字符串。唯一能找到可能重复记录的方法就是使用模糊匹配的逻辑,它可以计算字符串的相似度,接下来就设计一下方法:
首先要检查的是一些数据录入点,例如 City 、Postal cod e 和 Country 这类字段,这类字段一般是通过选择的方式录入的,系统一般不会让用户自己拼写这些数据,而且系统往往也会检查这些数据的逻辑规则是否正确。无论做何种检查,都需要有一些数据正确的列,否则没有信息能把重复的数据关联起来。
在上图里,城市和国家是正确的数据(至少不会拼写错误)。如果没有这种把可能重复的数据联系到一起的准确数据,排重是根本不可能的。排重工作下面要做的事情就是要保证有充足的计算能力。检查可能的重复记录意味着要搜索表里的全部记录。如果表里有一百万条记录,检查一条记录就要检查一百万次(1 百万 ×1 百万),如果要比较多个字段,情况会更糟。这就是为什么市场上这类工具的价格这么高的其中一个原因。价格高的另一个原因是这类工具都有内置的“知识库”,可以自动地匹配正确的地址和人名信息。
这里设计的方法包含三个步骤,当然也可以再增加步骤或做一些修改。这里主要的步骤就是上面提到的模糊匹配步骤。这个步骤完成下面的工作:
- 从数据流里读取输入字段。
- 使用某一种模糊匹配算法查询另一个数据流里的一个字段。
- 返回匹配结果。
接下来将详细介绍如何使用模糊匹配组件对数据的“模糊匹配”,具体操作如下:
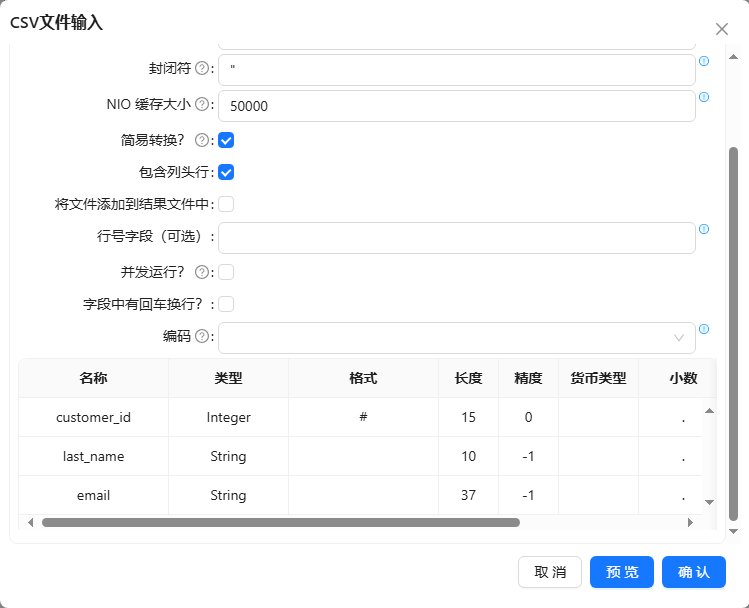
- 新建转换,将csv 文件输入组件拖至画布,双击组件,步骤名称填入“ReadSource”,获取需要的客户号、客户姓氏和邮件并将字段名更改以便后期区分,将使用【last_name】字段作为模糊匹配字段,使�用【e-mail】字段作为参照字段。 配置如下图所示:
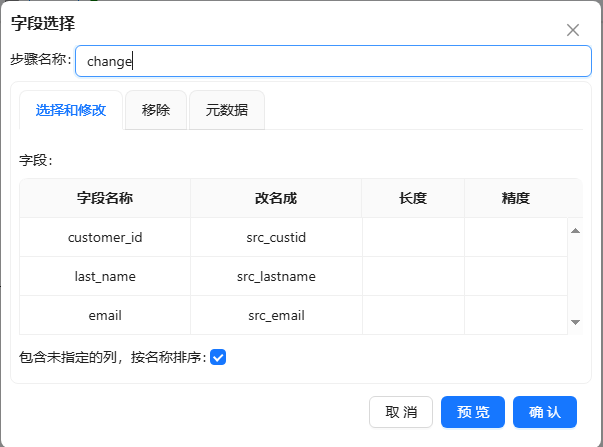
- 使用字段选择组件更改字段名,将字段选择组件拖至画布,双击组件,步骤名称填入“change”,获取需要的客户号、客户姓氏和邮件并将字段名更改以便后期区分,将使用【last_name】字段作为模糊匹配字段,使用【e-mail】字段作为参照字段。 配置如下图所示:
- 将csv 文件输入组件拖至画布,双击组件,步骤名称填入“Lkp_LastName”,获取需要的客户号和客户姓氏并将字段名更改以便后期区分,配置如下图所示:
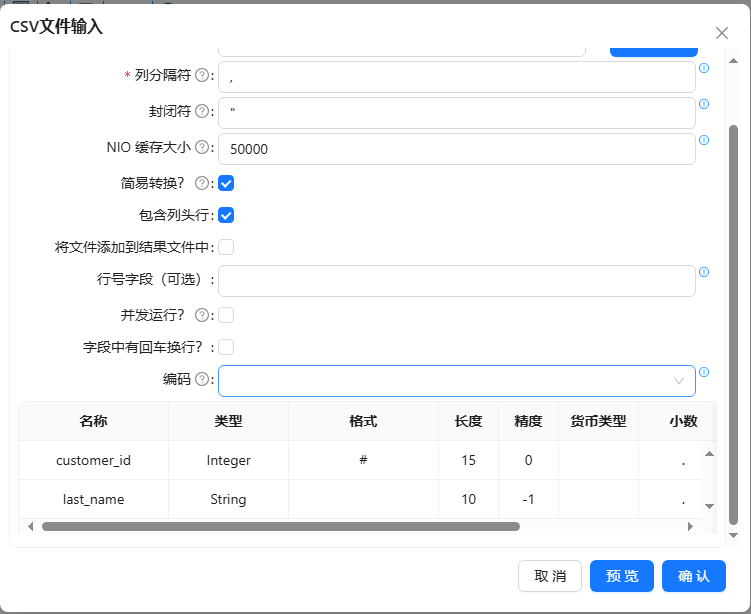
- 更改字段名,将字段选择组件拖至画布,双击组件,步骤名称填入“change1”,获取需要的客户号、客户姓氏和邮件并将字段名更改以便后期区分,将使用【last_name】字段作为模糊匹配字段,使用【e-mail】字段作为参照字段。 配置如下图所示:

- 将模糊匹配组件拖至画布,两个表输入组件与其连接,双击组件,步骤名称填入“MatchLastName”,填入之�前准备好的匹配字段和主要流字段,并使用“Jaro Winkler”算法,设置的最小相似度为 0.8。“设置”栏里的选项,主要取决于选择的算法。如果你选择的是“Soundex”或“Metaphone”算法等,是没有设置项,“区分大小写”选项也只适用于“Levenshtein”算法。 具体配置如下图:
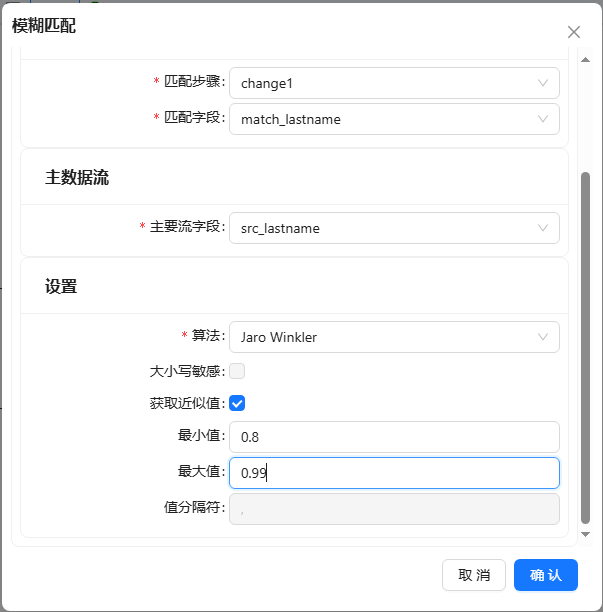
设置中其他的一些选项都是用来控制匹配结果的。这里的“获取近似值”选项很重要,这个选项可以只返回一个最相似的数值。如果不选中这个选项,就会返回相似度在最小值和最大值之间的多个数值,多个值使用指定的分隔符分开。
- 选择“字段”标签,设置查询流里需要的其他字段,填入匹配字段与值字段,如下图所示:

在“字段”标签下可以设置匹配列的列名。但因为有多个匹配的数值,以及这些数值也没有可以参照的主键或引用,所以这个结果对后续处理没有太大作用。对于排重工作来说,不但要找到相似的数值,还要知道这些数值属于哪条记录。所以最好选中“获取近似值”选项。这个选项只返回相似度最高的数值,另外还返回这个数值所在记录的其他字段。
在这个例子里,模糊匹配是第一个步骤。在现实情况中,这个步骤的前面可能还有一些使用正则表达式匹配等技术做数据清洗的步骤。例如,一个数据源文件只包含了一个单一的 name 字段,这是人的全名。如果是美国人名,这时就需要使用正则表达式步骤把这个字段��拆分成“first name”、“middle initial”和“last name”字段,如果是其他国家的人名,可能有其他的拆分方法。
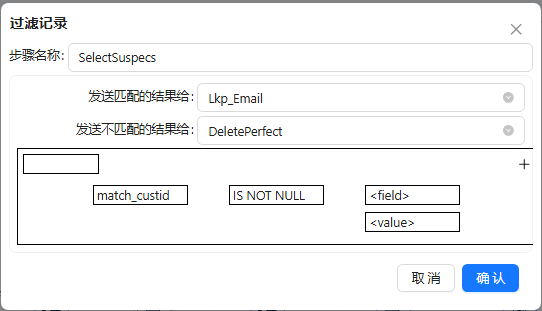
- 将过滤记录组件拖至画布,让模糊匹配步骤与其连接,再将 空操作(什么也不做) 组件拖至画布,并将步骤名改为“DeletePerfect”,将数据库查询组件拖至画布,步骤名改为“Lkp_Email”;然后将过滤记录连接这两个步骤以便接下来的配置,双击组件,步骤名称改为“SelectSuspecs”,选择数据发送的步骤和条件,具体如下图所示:
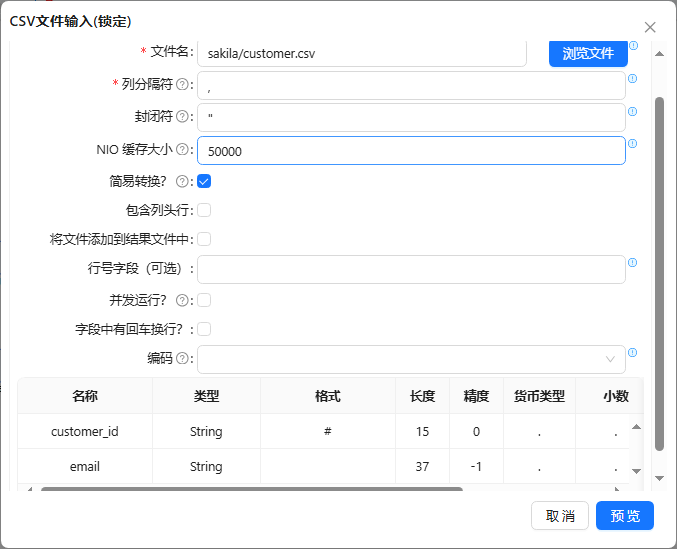
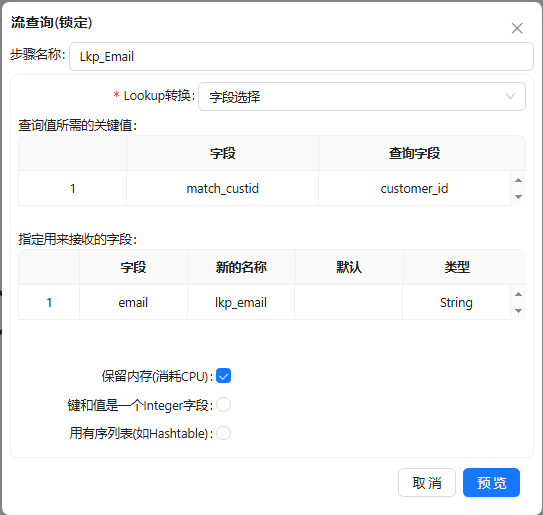
- 将csv 文件输入组件拖至画布,与字段选择组件连接,接入流查询组件,双击Lkp_Email步骤,选择好所需的关键字条件和要返回的值,具体如下图所示:

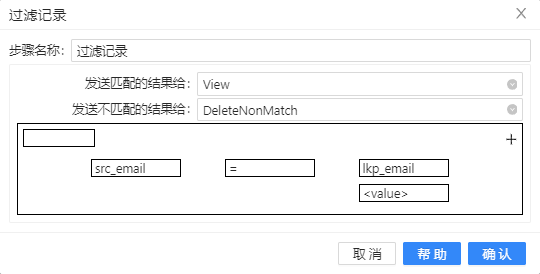
- 将过滤记录组件拖至画布,让数据库查询步骤与其连接,再将空操作(什么也不做)组件两次拖至画布,并分布将步骤名改为“View”和“DeleteNonMatch”;然后将过滤记录连接�这两个步骤以便接下来的配置,双击组件,步骤名称改为“RemoveWaste”,选择数据发送的步骤和条件,具体如下图所示:
记录是“可能的”重复记录,尽管在这个例子里,可以很肯定说这两个记录是一个人。但实际情况中也有可能是一对夫妻共享了同一个电子邮箱地址。还有更糟的情况,例如,两个记录指向同一个人,但两个地址都是有效的,一个是街道地址,一个是邮局邮箱地址,或者一个人有两个电子邮箱地址等等情况。
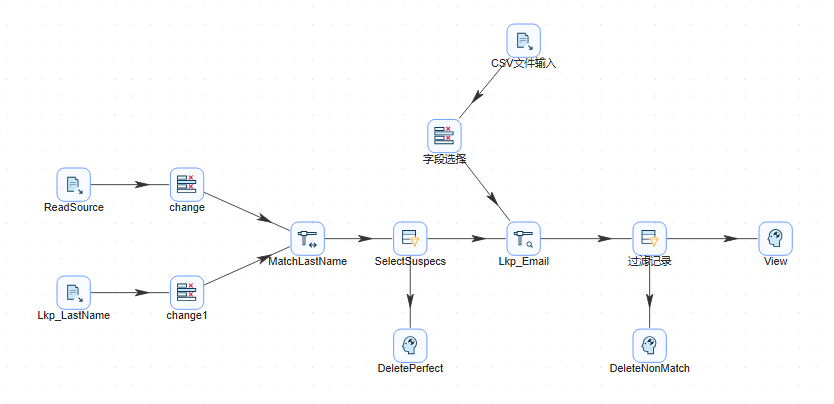
- 按顺序连接,若提示选择步骤,依然选择主输出步骤。完整转换如下图所示:
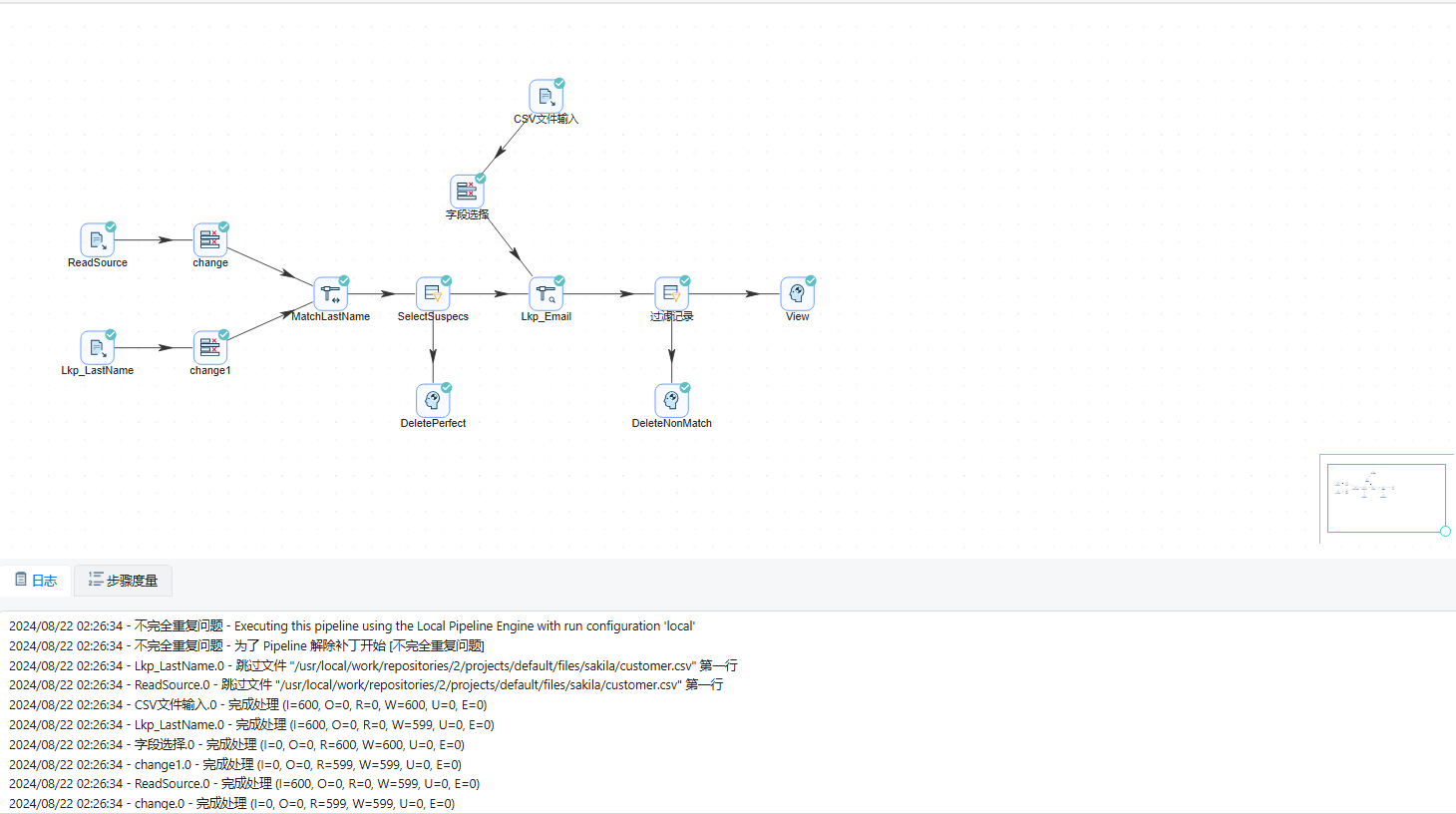
- 运行转换,结果如下图所示:
- 选中DeletePerfect步骤,右击并选中预览查看没有匹配到姓氏相近的数据信息。结果如下图所示:
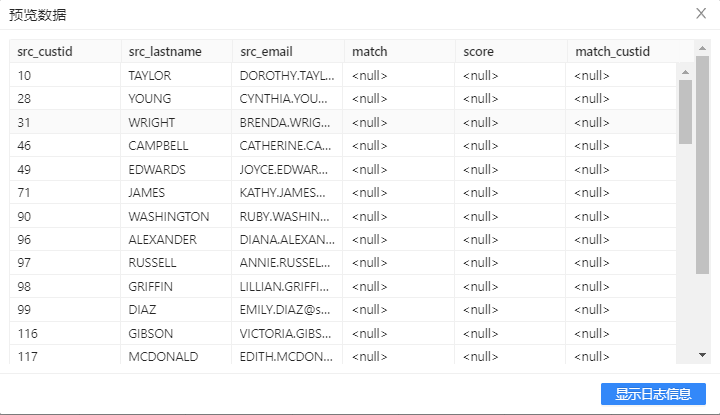
- 选中DeleteNonMatch步骤,右击并选中预览查看通过匹配后姓氏相近,但邮件不相等的数据信息。结果如下图所示:
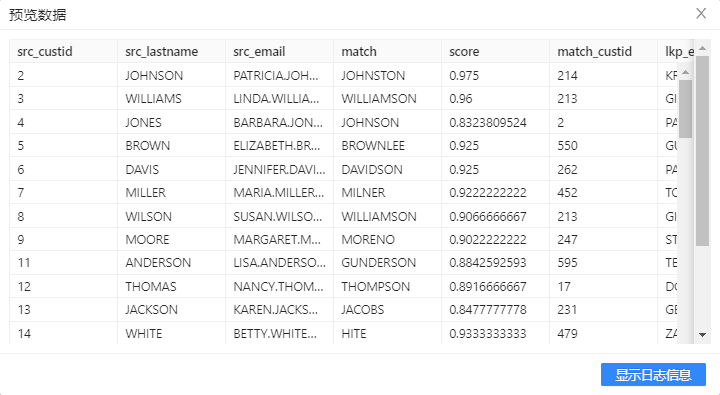
- 选中View步骤,右击并选中预览查看通过匹配后姓氏相近、邮件相等的数据信息。结果如下图所示:
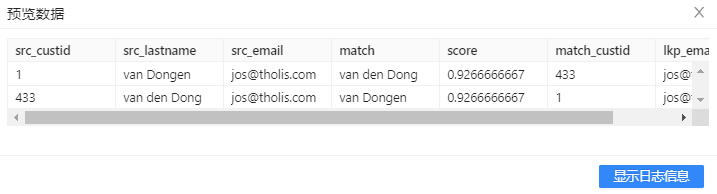
排重的另一个问题是正确性的问题:即使找到了不同地址或不同电话号码的重复记录,那么哪一个地址或电话号码是正确的?不是所有的业务系统对字段的变化都有详细的变更日志,即使有,还有人为错误输入的可能。把多个记录合并成一个记录要非常小心。首先,要确定以哪条记录里的数据为准。其次,地址应该作为一个整体来处理,如果把一条记录的城市名称,合并到另一条城市名称为空的记录里通常没有太大意义,以上是一个基本的排重转换,实际应用场景还需要结合业务来处理。