参照表清洗
案例说明
在很多场景下,如更正地址信息等,需要访问外部的主数据或参照数据(或字典表)。基础数据类的应用一般都使用这些数据,如显示出标准的国家名和州名。但很多其他类的应用,数据并不规范。
例如,在某客服系统中,只能通过文本输入的方式输入产品信息。为了清理这些数据,就需要把文本方式输入的产品名称和主数据里的产品名称进行匹配,主数据里的产品名称是最完整和标准的。最常用的使用主数据的场景就是做地址更正。通常这些地址主数据都是使用订阅方式才能得到的,某些公司维护和销售这些地址主数据。
参照表有很多用途,一个最常见的用途就是做数据的查询和检验。提供一个输入字段,如果输入字段里的值没有匹配上,就给�对应的数据行做一个错误标志。因为只需要找出错误的数据,所以返回的数据都是有限的错误数据。为了提高成功查询的比例,在做查询之前,最好先使用其他步骤清洗数据。我们使用城市和邮政编码查询做个例子。几乎所有国家都有邮政编码体系,邮政编码连接到区域、城市或特定的街道(如荷兰)。德国的邮政编码体系是世界上最精准的,通过邮政编码和门牌号就能定位到一个唯一的地址。但人们输入邮政编码时,有时会犯错误,所以要检验邮政编码和地址是否匹配。
使用参照表清洗地址信息
本小节将介绍如何使用流查询来判断地址和邮政编码是否匹配,具体操作如下:
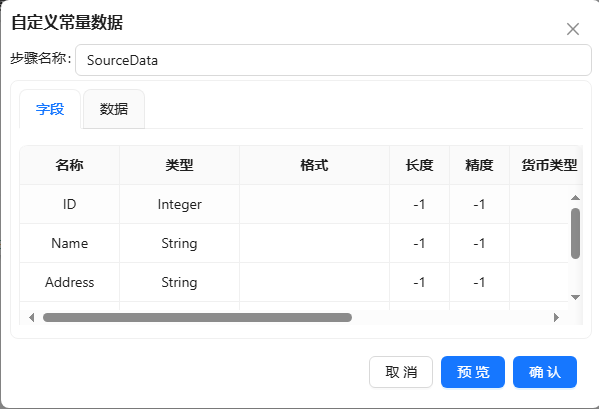
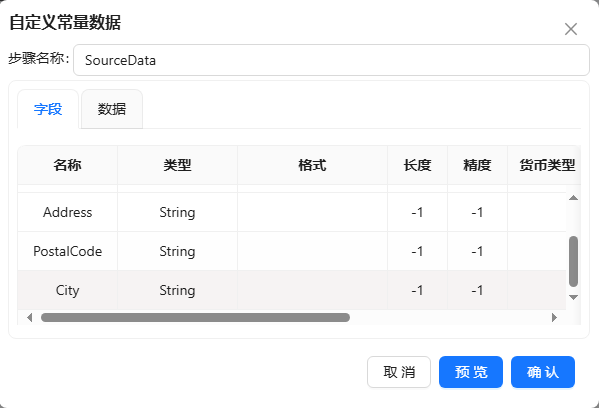
- 新建转换,将自定义常量数据拖至画布,使用该组件生成数据。双击组件,步骤名称填入“SourceData”,在“元数据”中先定义【ID】、【Name】、【Address】、【PostalCode】和【City】五列并选择好数据类型,如下图所示:
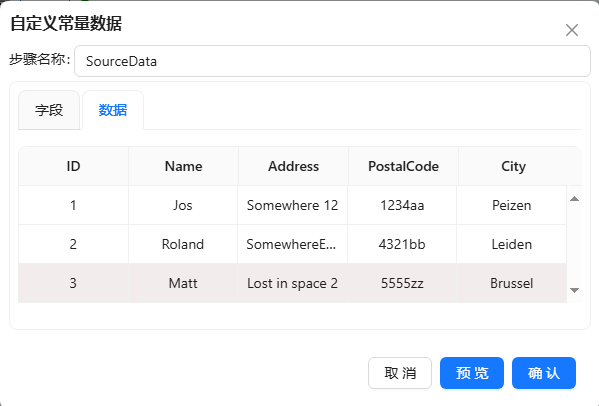
- 选择“数据”标签,输入如下图所示的三条数据:
- 第一个清洗步骤就��是从邮政编码里提取数字。将计算器组件拖至画布,双击组件,步骤名称填入“getPC4”,在计算里选择“Return only digits from string A”,把【PC4】作为字段 A,新增加一个字段保存这些数字,字段名使用像【PC4】这样有业务含义的字段名,具体配置如下图:
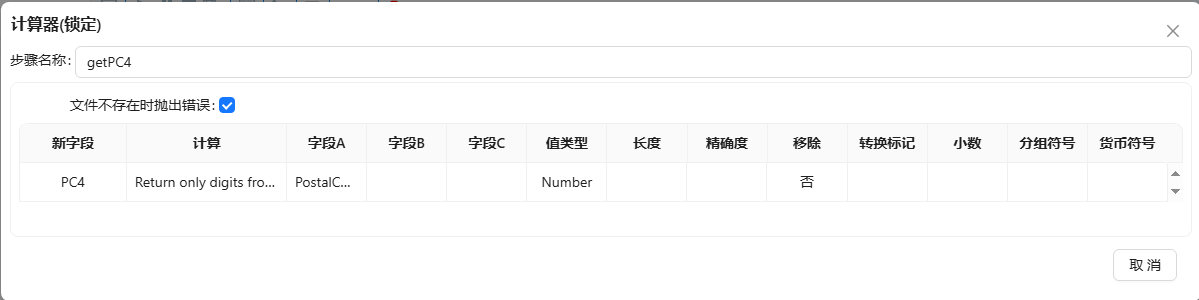
- 使用自定义常量数据来模拟一个查询的参照表,将自定义常量数据拖至画布,双击组件,步骤名称填入“PC4”,插入如下图所示字段:
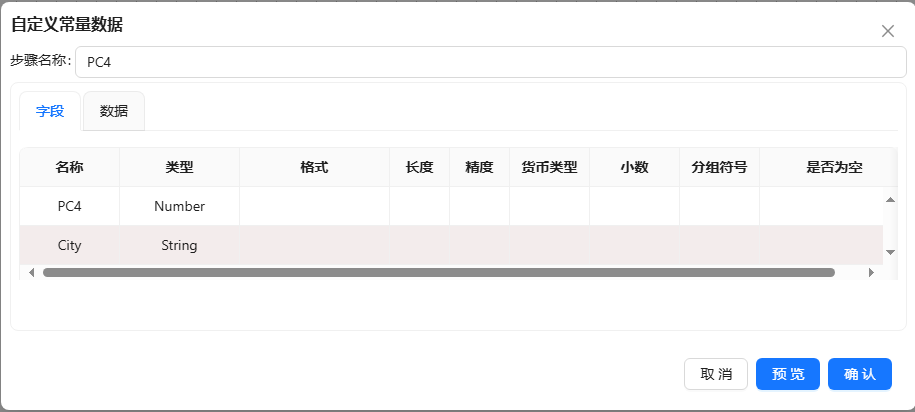
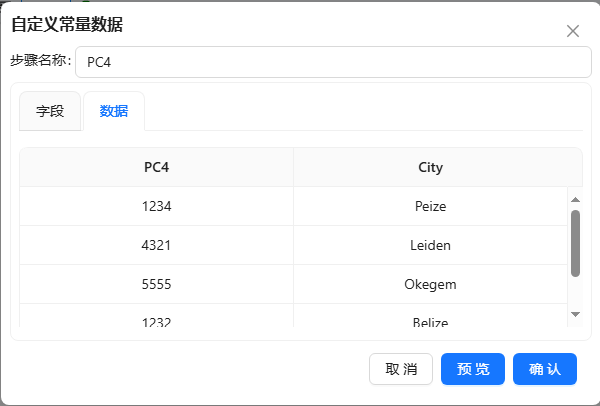
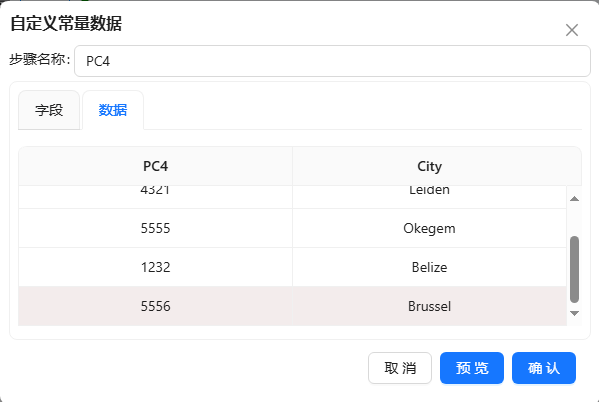
- 选择“数据”标签,输入如下图所示数据:
- 根据【PC4】字段里的四位数字,使用流查询步骤从参照表中查询城市名称。将流查询拖至画布,并且把“PC4”和“getPC4”步骤都连接到流查询组件,双击组件,按下图配置:
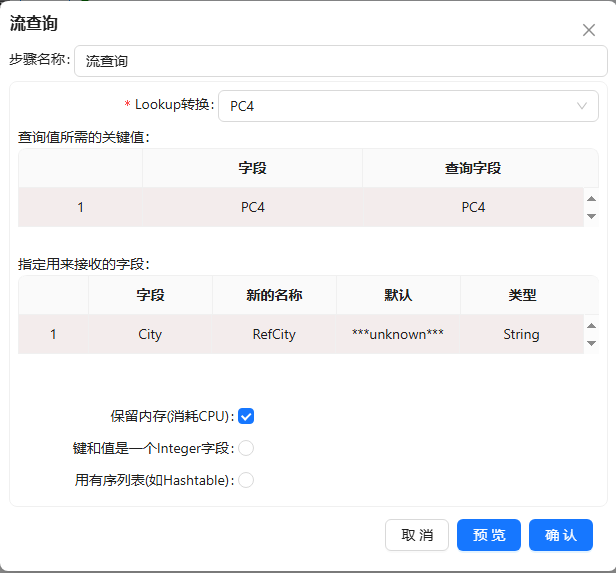
流查询从参照表也就是PC4步骤中查询数据,流查询步骤会根据设置的关键字段在参照表中查询对应的值(【City】字段)并将结果返回到新增的字段【RefCity】中。
在实际应用场景中,可能要查询的数据在参照表中不存在。为了后面再处理这些未被查询到的数据,建议设置一个容易识别的默认值,如设置的默认值的前缀和后缀都是***。这样可以在检查数据的时候比较容易找到这些异常数据,而且查询后在模糊匹配原始输入的城市名时,这个默认值不会和原来的任何城市名有相似度
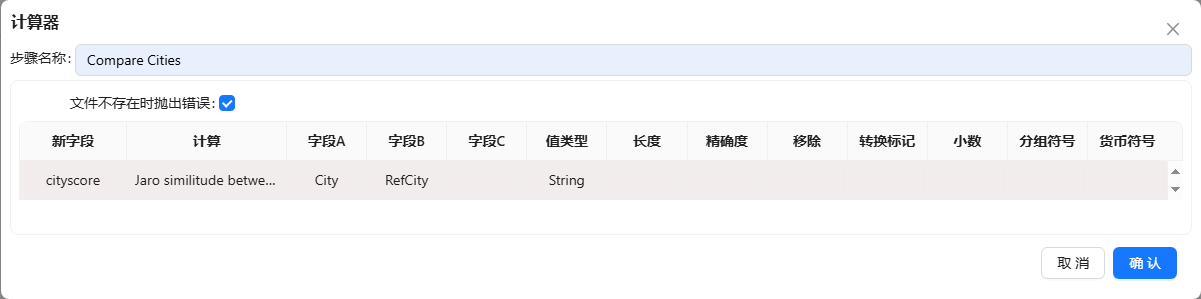
- 接下来进行的模糊匹配的目的主要是为了检查一些拼写或完整性错误,需要再使用另一个计算器步骤。将计算器组件拖至画布,双击组件,步骤名称为“Compare Cities”,把【City】和【RefCity】作为字段 A 和字段 B,使用 Jaro-Winkler 匹配算法,计算选择“JaroWinkler similitude between String A and String B”,新生成的字段命名为【cityscore】,具体配置如下:
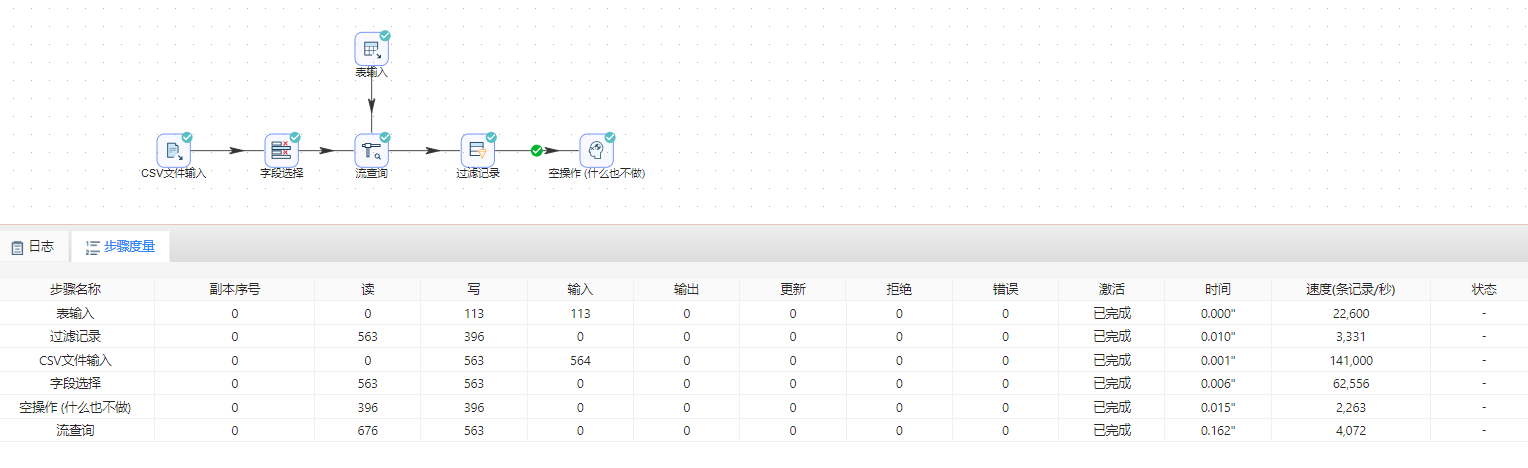
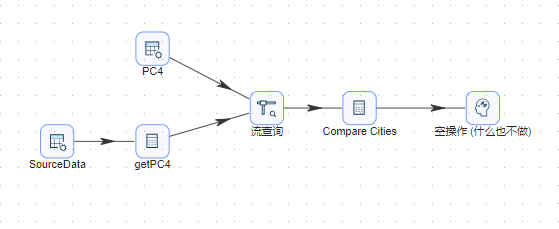
- 将 空操作(什么也不做) 组件拖至画布,并按顺序连接,选择主输出步骤连接线类型。完整转换如下图所示:
- 运行转换,结果如下图所示:
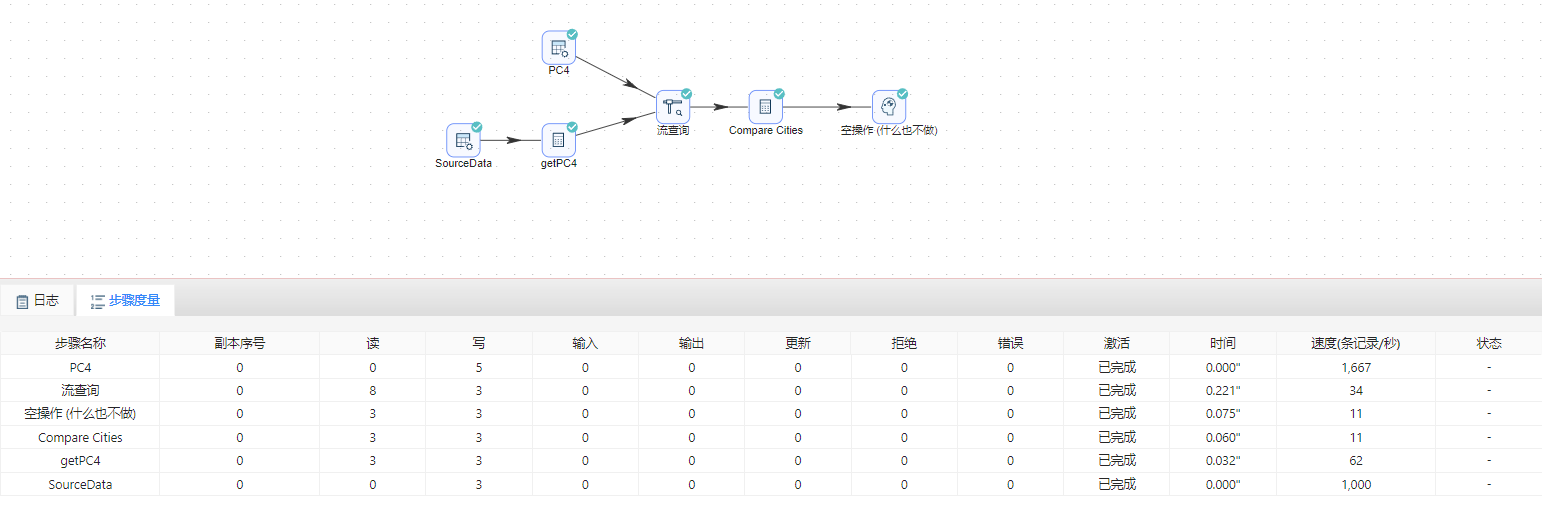
- 选中 空操作(什么也不做) 组件, 右击并选中��预览查看数据。结果如下图所示:
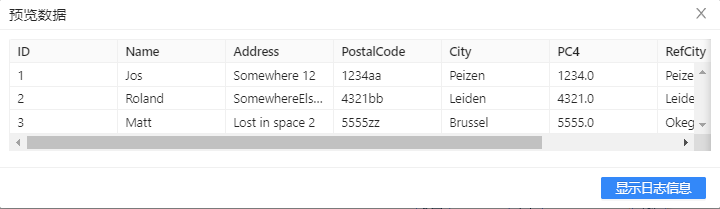
可以观察到第一条记录原始数据和参照数据的相似度非常高,这里可能有一些拼写错误。
第二条记录是完全正确的。
第三条记录看上去有一些问题:城市名称完全不同,另外相似度非常低(一般低于 0.8 就要怀疑了)。但从数据里并不能判断出错误在哪里:是邮政编码对了城市名错了?还是城市名对了邮政编码错了?为了得到结论,还需要做一次相反的校验,“相反”校验是指根据城市名称再去参照表里找邮政编码,然后再和原始数据的邮政编码比较,如果邮政编码非常近似(如返回的邮政编码是 5556),就可以得出结论,是邮政编码拼写错误。
当然很多应用中,在用户输入地址、邮政编码和城市名时,都会自动检查它们之间的组合是否正确。但大部分企业都是在它们内部的应用里做这些检查,而面向客户的网站一般允许很多不一致的数据,这样把不同来源的数据整合到一起就比较困难了。
参照表清洗性别编码
有一种参照表叫数据确认主表,性别编码就是这种参照表的例子。
有的系统使用字母 M、F 和 U,分别代码男、女、未知,有的系统使用 NULL 来代表未知的性别,有的系统使用 Male 和 Female 代表男, 女,而有的系统则使用完全不同的编码,如 0(男)、1(女)或 0(未知),1(男)、2(女),等等。还有更复杂的情况,有的系统使用 C 代表儿童,�使用 F 代表父亲,M 代表母亲,各种变化和组合都有可能。
要把从这些来源的数据整合到一起,要有一套统一的编码规范,然后把已有的编码映射到规范的编码上。使用单一的查询表比每个系统都有一个查询表要更好,便于维护。 这里要满足两个基本的需求:
- 源系统中的每个可能的值都需要映射;
- 要映射到唯一的一组值;
基于上述性别的例子,接下来将介绍把数据整合到一起成统一的编码规范,具体操作如下:
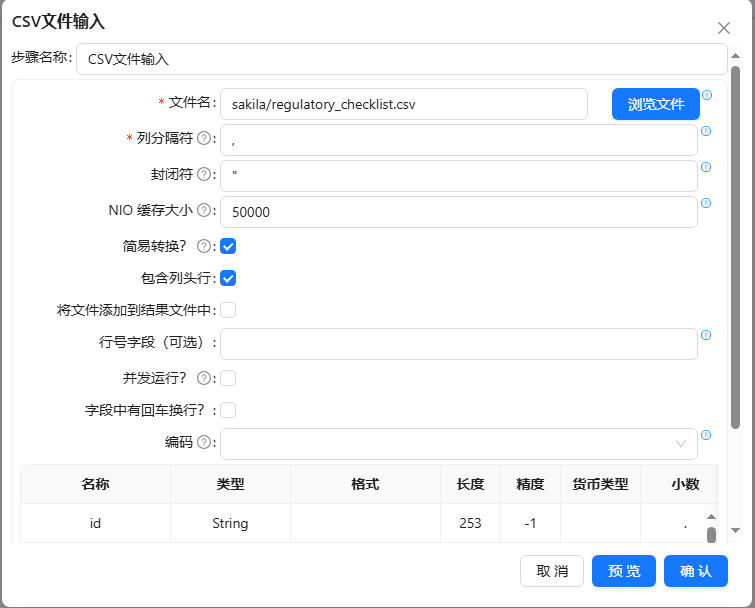
- 新建转换,将CSV 文件输入组件拖至画布,双击组件,点击“浏览文件”上传,更改“列分隔符”,并在底下空白处右击后选择“获取字段”以此获取到所有字段信息,具体配置如下图:
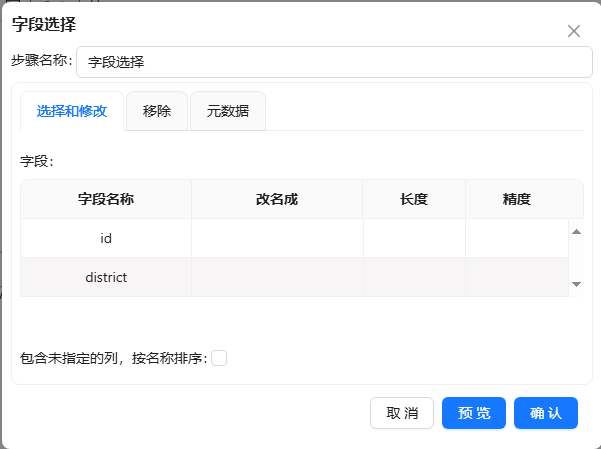
- 将字段选择组件拖至画布,双击组件,步骤名称为“字段选择”,并点击“选择和修改”标签,在空白处右击后选择“获取选择的字段”,此时将显示所有的字段信息,删除不需要的字段:
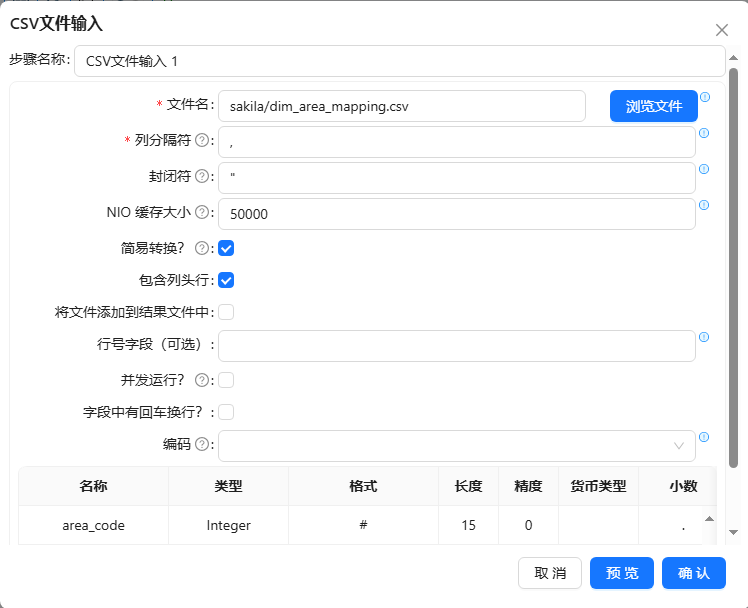
- 将CSV 文件输入组件拖至画布,提取参照表中【area_code】和【l_area_name】数据,【area_code】字段是要获取的标准数据:
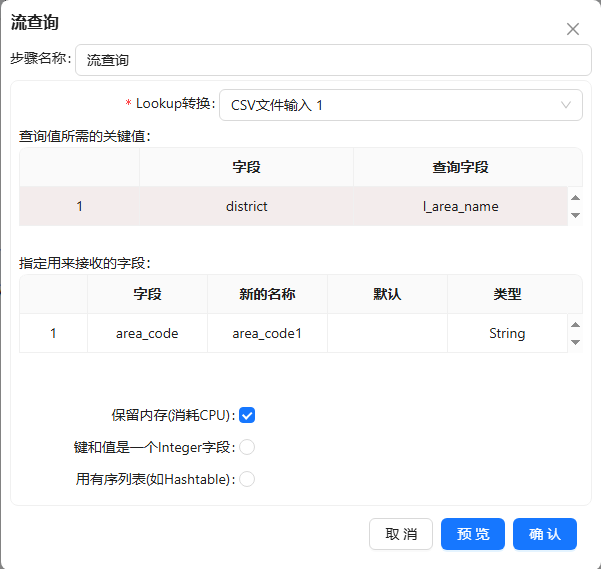
- 根据【src_code】字段里的数据,再使用流查询步骤��从“表输入”提取的数据中查询信息。将流查询控件拖至画布,并把“表输入”和“字段选择”步骤都连接到流查询步骤,双击组件,按下图配置:
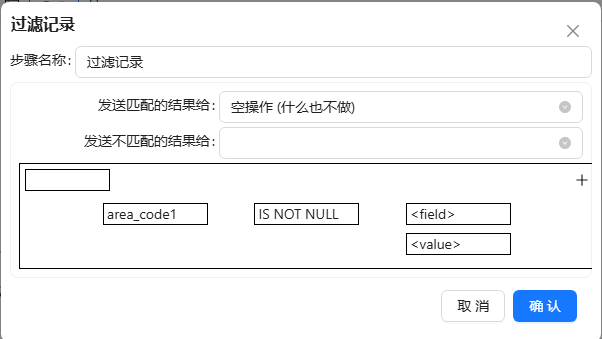
- 将过滤记录拖至画布,过滤掉没有查询到的 area_code,配置如下图所示:
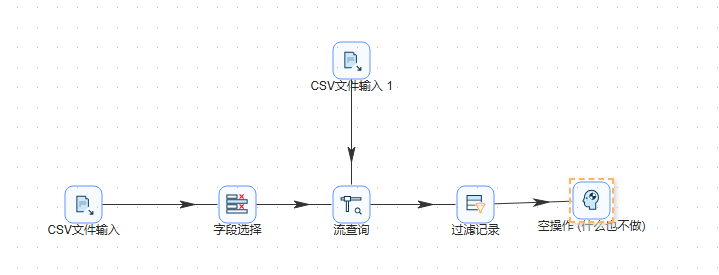
- 将空操作(什么也不做)组件拖至画布,并按顺序连接。若提示选择步骤,依然选择True 输出。完整转换如下图所示:
- 运行转换,结果如下图所示: