字段选择、匹配、过滤及排序
案例说明
数据清洗是使用 ETL 工具最重要的原因之一,数据清洗是数据质量这一更大主题的一部分,而数据质量又是数据管理这一主题的一部分。设计可复用的数据清洗转换是 ETL 开发过程 中的一个重要部分。 UDI Studio 提供了丰富的组件,帮助完成数据清洗工作,本案例将介绍如何使用这些组件进行数据清洗。
数据准备
本案例中“对足球比赛数据进行过滤、排序、选择”小节将使用足球比赛数据:matches.txt;
本案例中��“使用模糊匹配检验错误数据”小节将使用states_of_usa.txt、usa_city.txt数据;
对数据进行字段选择、排序、过滤
本小节主要对“matches.txt”数据进行排序,通过指定字段对比赛数据进行排序,能够更好的观察比赛情况。
使用排序记录组件,可以对原有数据进行排序,使用过滤记录组件可以过滤出满足条件的记录。具体操作如下:
-
新建转换工作流,从输入中拖入CSV 文件输入组件到画布。点击浏览文件,选择 matches.txt,列分隔符使用英文字符
;,在表格右键菜单中选择获取字段,初始化字段数据,其余参数保持默认。配置如下图所示: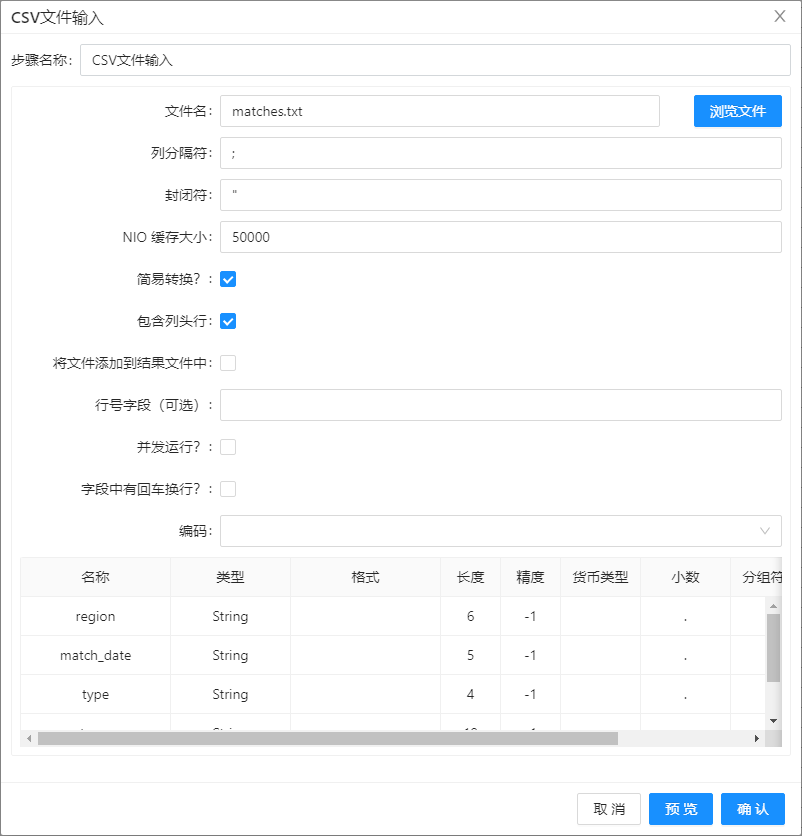
-
点击预览,查看数据,预期结果如下图所示:
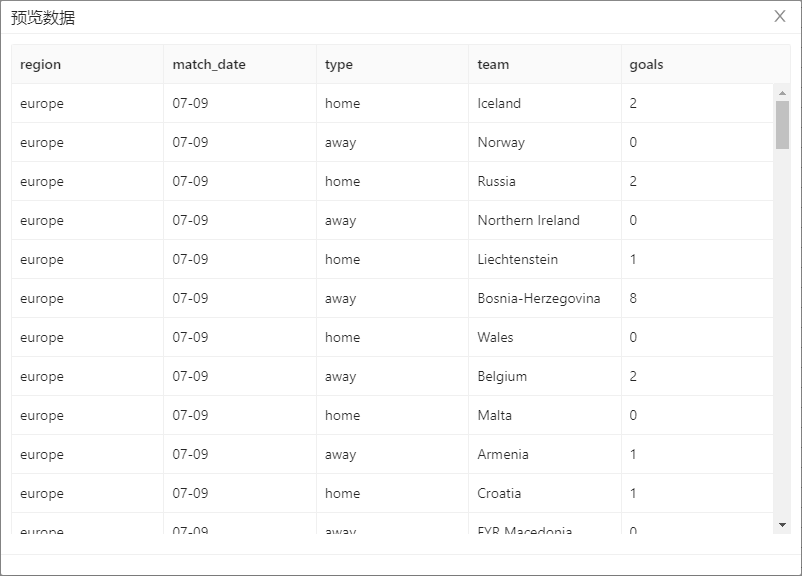
-
从转换中拖入字段选择组件到画布并连接上一步骤,连接线采用“主输出步骤”。在字段选择组件的选择和修改标签页的表格右键菜单中,选择获取字段,初始化字段数据。选中表格中的 region 记录并删除。保留其他字段记录,配置如下图所示:
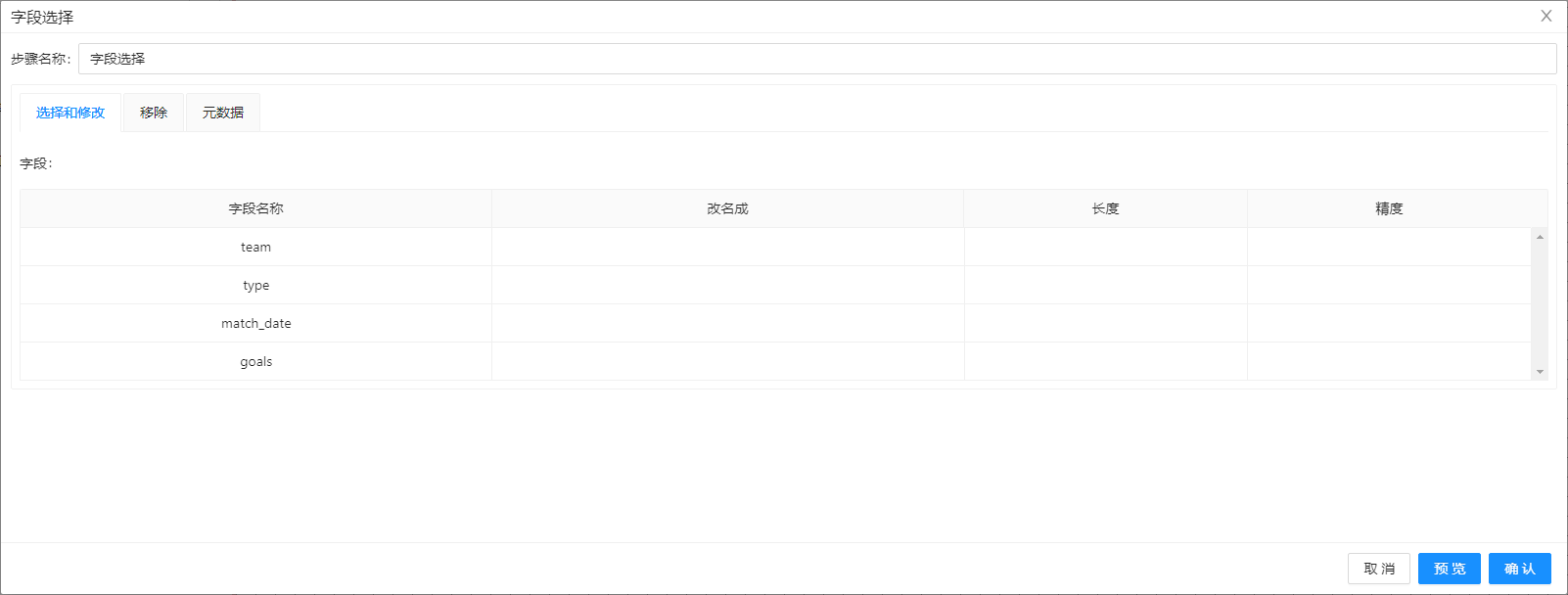 4. 拖入排序记录组件到画布,并连接上一步骤(字段选择),双击该组件,设置team、type为排序字段,升序排序,配置如下图所示:
4. 拖入排序记录组件到画布,并连接上一步骤(字段选择),双击该组件,设置team、type为排序字段,升序排序,配置如下图所示:
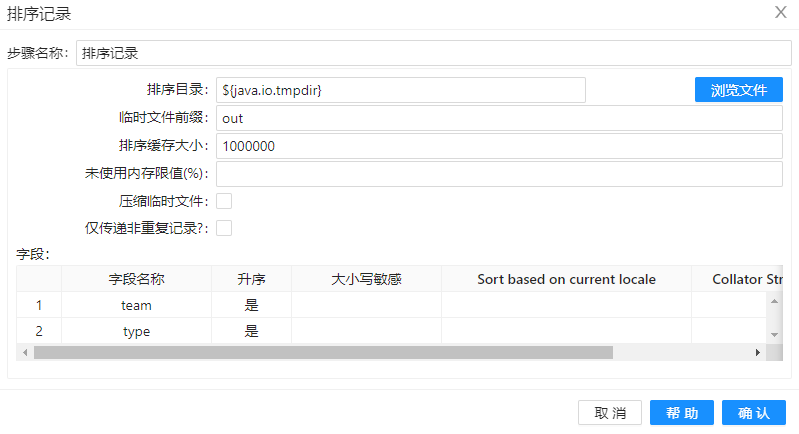
5. 在流程中拖入 过滤记录 和 空操作(什么也不做) 组件,依次连接步骤,均采用主输出步骤进行连接。整体转换如下图所示:
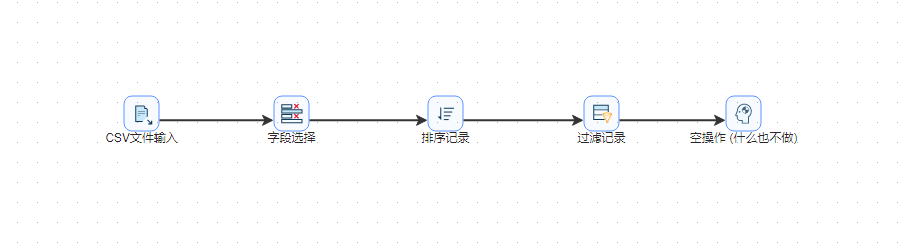
6. 双击过滤记录组件,使用 match_date 字段作为过滤条件,输入 07-09 作为过滤值,配置如下图所示:
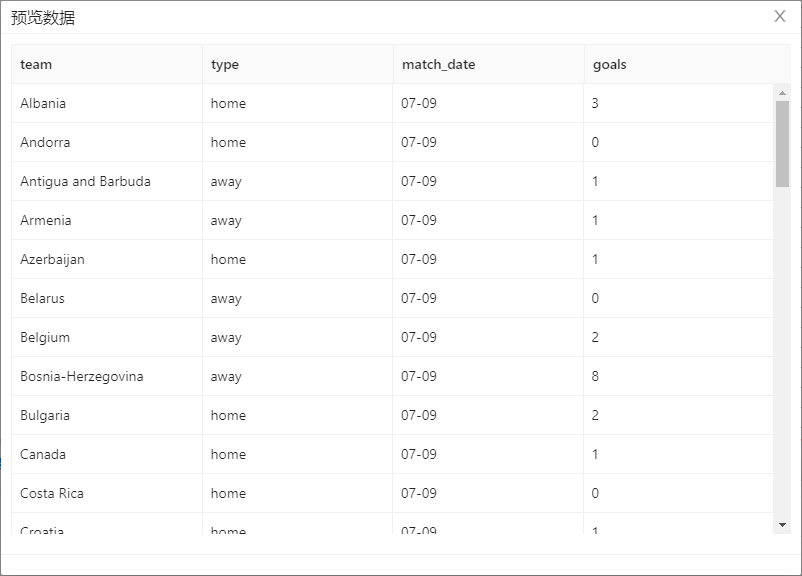
- 运行转换,结果如下图所示,可以看到 matches.txt 文件中有 242 条记录,经过过滤后的结果中只包含 56 条 7 月 9 日的比赛数据。
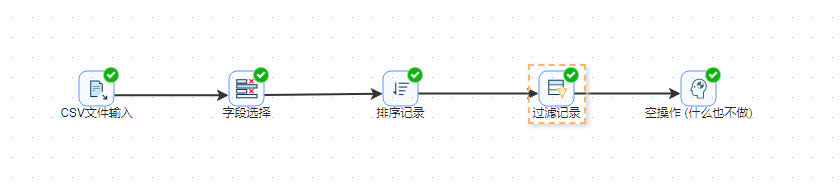

- 选中 空操作(什么也不做),右击选择预览查看数据,结果如下图所示,预期输出中 matches.txt 文件的 region 字段已经被删除,记录已经按照 team、type 字段进行升序排序。
使用模糊匹配检验错误数据
本案例使用模糊匹配可以查找出那些可能输入错误的数据,为错误数据的修正提供参考
使用CSV 文件输入读取一个包含国家名信息的文件,用另一个CSV 文件输入读取一个包含标准国家名的文件。通过模糊匹配来查询可能输入错误的国家名,并输出两者之间的距离。
具体操作如下:
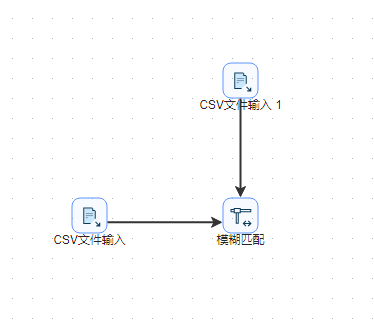
- 从输入中拖入两个CSV 文件输入组件到画布,在应用中再拖入模糊匹配组件,连接如下图所示:
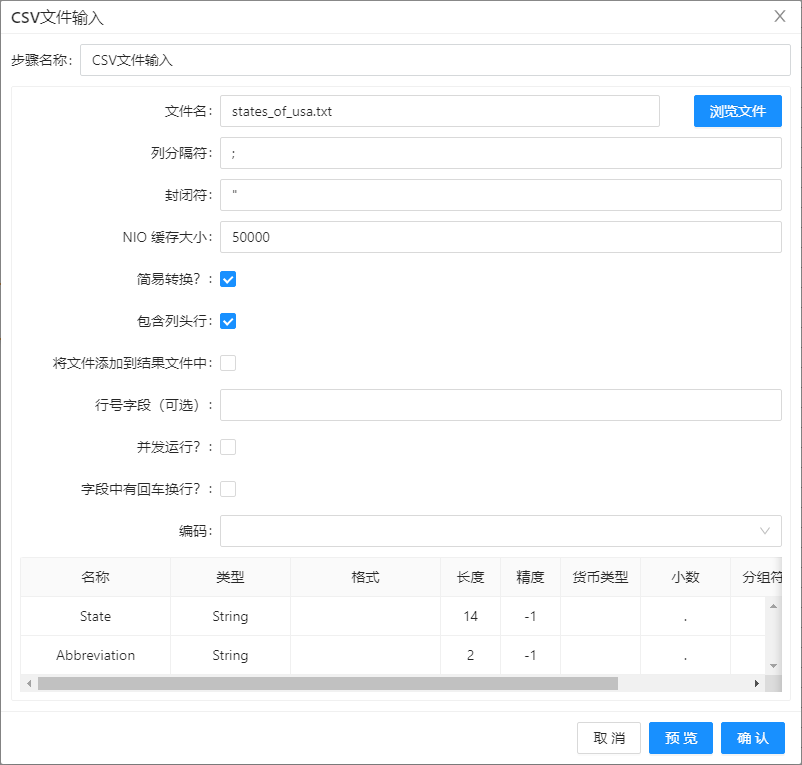
- 双击第一个CSV 文件输入,选择 states_of_usa.txt 作为输入文件,列分隔符使用英文字符
;,在表格右键菜单中选择获取字段,初始化字段数据,配置如下图所示,点击确定。
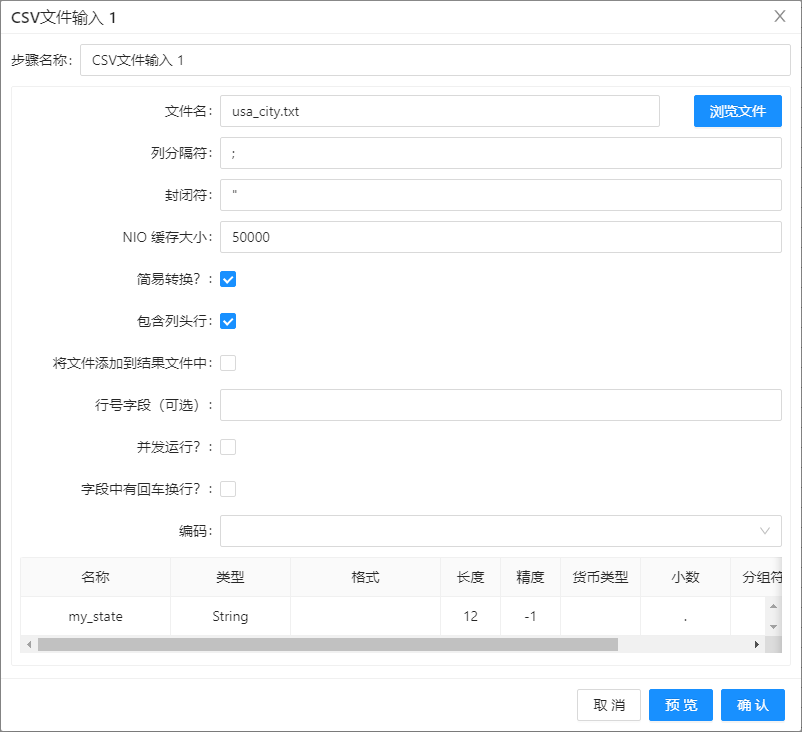
- 双击第二个CSV 文件输入 ,选择 usa_city.txt 作为输入文件,列分隔符使用英文字符
;,在表格右键菜单中选择获取字段,初始化字段数据,配置如下图所示,点击确定。
- 双击模糊匹配,配置如下图所示:
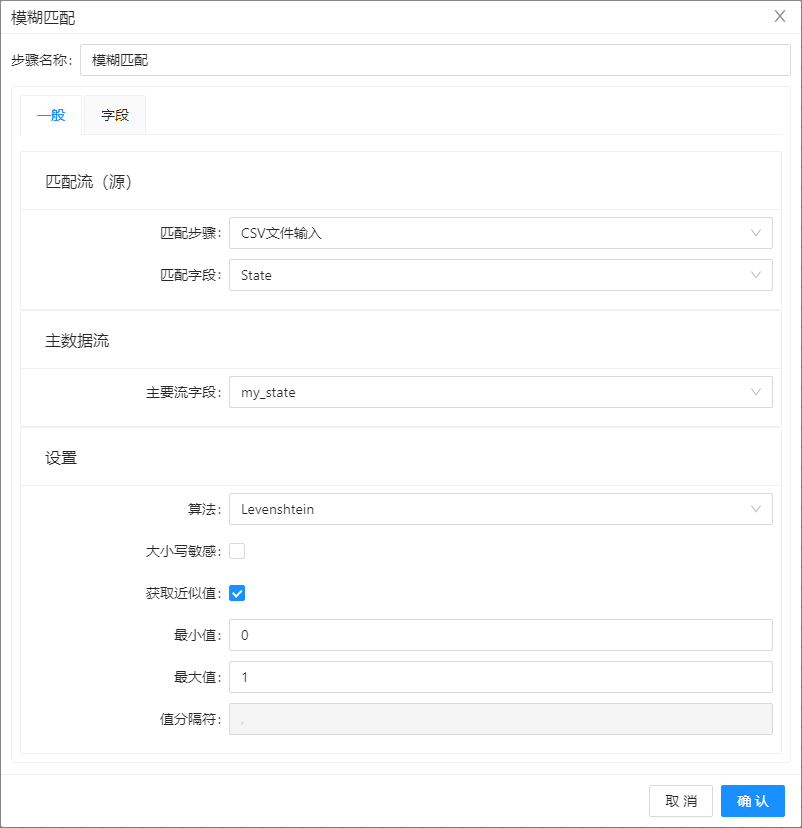
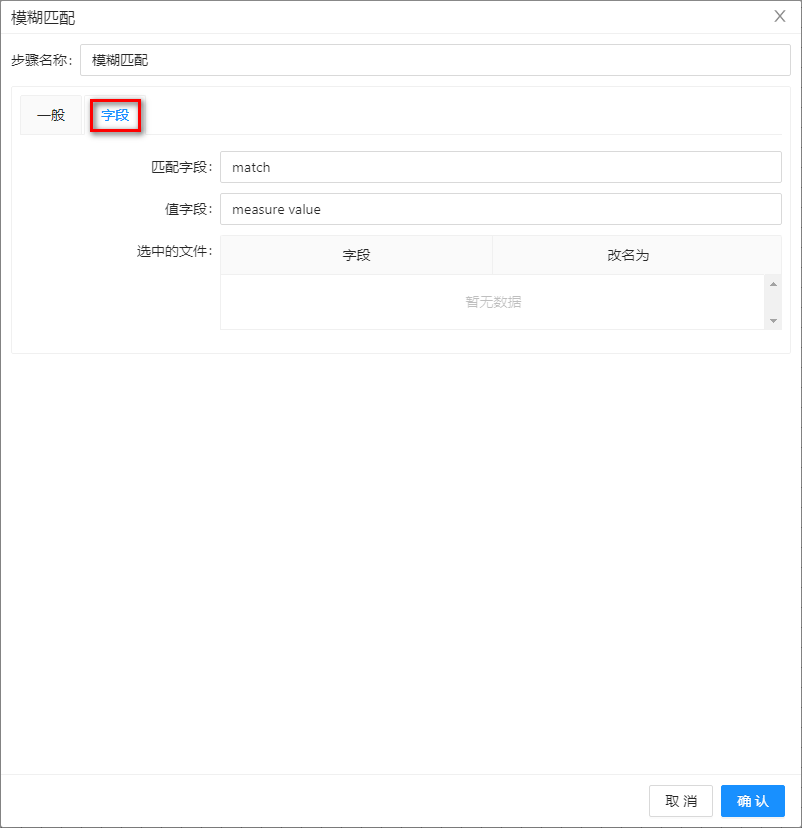
- 选择字段标签,在匹配字段文本框中输入match,在值字段输入measure value,如下图所示:
- 运行转换,结果如下图所示:
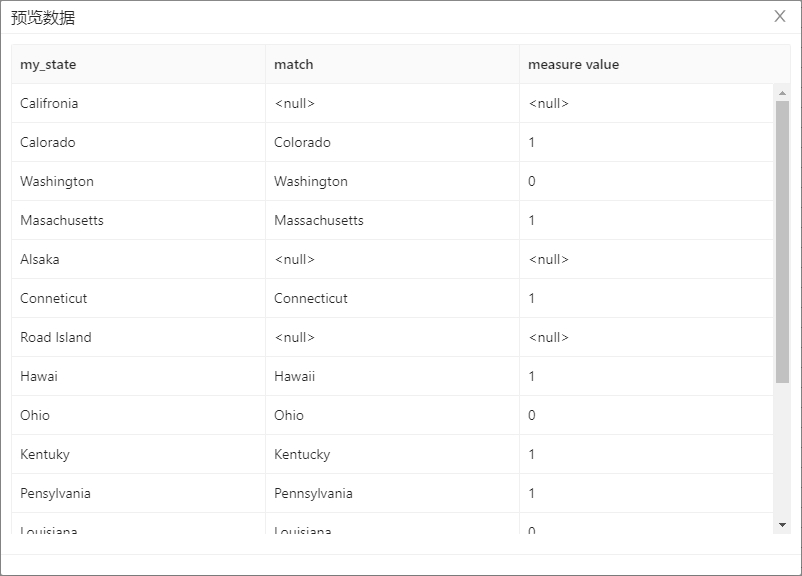
 7. 选中模糊匹配并预览数据,结果如下图所示:
7. 选中模糊匹配并预览数据,结果如下图所示: