文本增强
组件介绍
“文本增强”(Word Enrichment) 控件对文本数据集进行词富集分析。
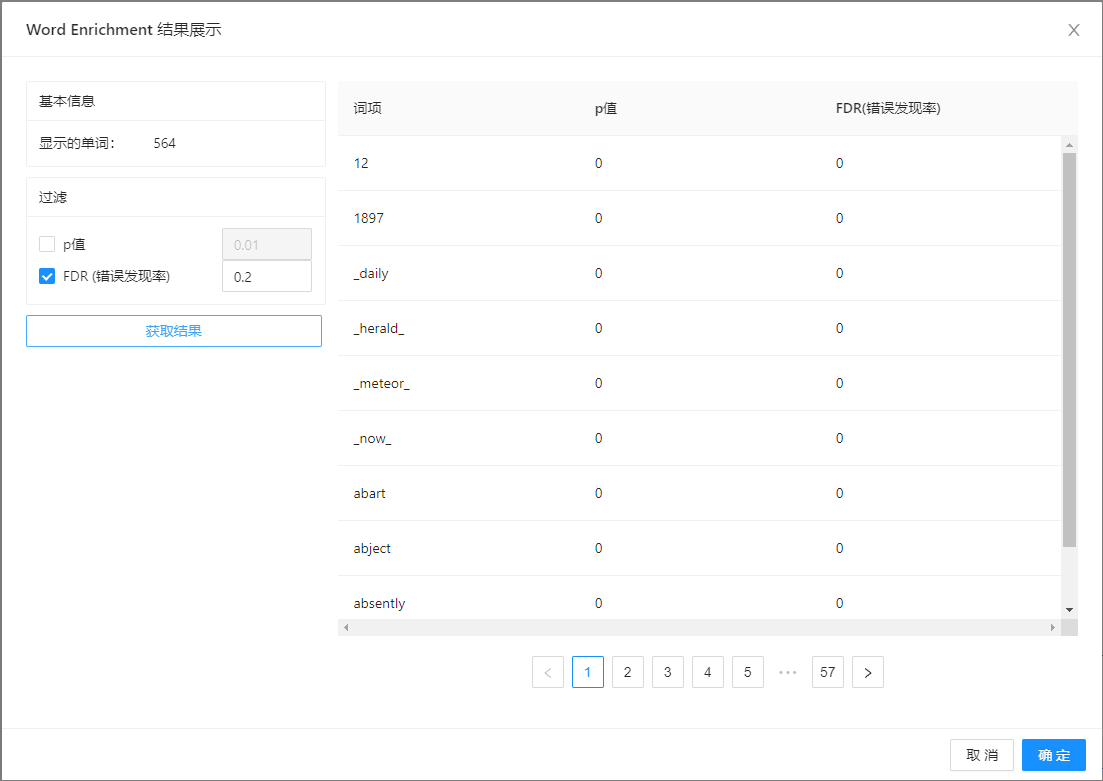
“文本增强”(Word Enrichment) 控件显示选中子集 p 值列表。p 值越低,表明所选子集单词是重要的可能性更高。FDR(错误发现率)与 p 值相关联,表示的是预测集合中错误预测的预期百分比,即低 p 值列表中的假阳性。
- 输入:
- sel:从语料库中选择的实例
- cor:文本数据集
- 输出:
- 无
页面介绍
点击 “文本增强”(Word Enrichment) 控件查看参数配置页面,如下图所示:

点击 “查看结果” 按钮,查看分析结果:
参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| 基本信息 | 显示的单词 | 单词个数信息 | |
| 过滤 | p 值 | p值:0 | p值:0.01 |
使用案例
在下图所示的案例中,使用 “加载语料库”(Corpus) 控件连接 “词袋”(Bag of Words) 控件,使用 “数据抽样”(Data Sampler) 连接 “词袋”(Bag of Words) 控件,使用 “数据抽样(Data Sampler)” 的输出smp、rmn分别连接 “文本增强”(Word Enrichment) 控件的sel、cor输入,
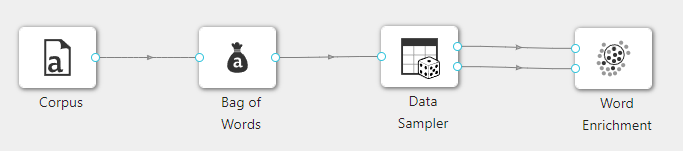
案例中 “加载语料库”(Corpus) 控件加载“book-excerpts”数据集, ��“词袋”(Bag of Words) 控件和 “数据抽样”(Data Sampler) 控件采用默认配置。 “文本增强”(Word Enrichment) 控件设置如下:过滤选择 FDR 值,设置为 0.2。运行结果如下图所示。