BIRCH
组件介绍
“BIRCH” 控件主要使用层次聚类算法来划分数据。
BIRCH(英文全称:balanced iterative reducing and clustering using hierarchies,中文:利用层次方法的平衡迭代规约和聚类)是一个非监督式分层聚类算法,于1996年由 Tian Zhang 提出。算法的优势在于能够利用有限的内存资源完成对大数据集的高质量的聚类。该算法通过构建聚类特征树(Clustering Feature Tree,简称CF Tree),在接下来的聚类过程中,直接对聚类特征进行聚类,而无需对原始数据集进行聚类。因此在多数情况下只需要扫描一次数据库即可进行聚类,IO成本与数据集尺寸呈线性关系。
- 输入:
- data:数据集
- 输出:
- data:处理后的数据集
页面介绍
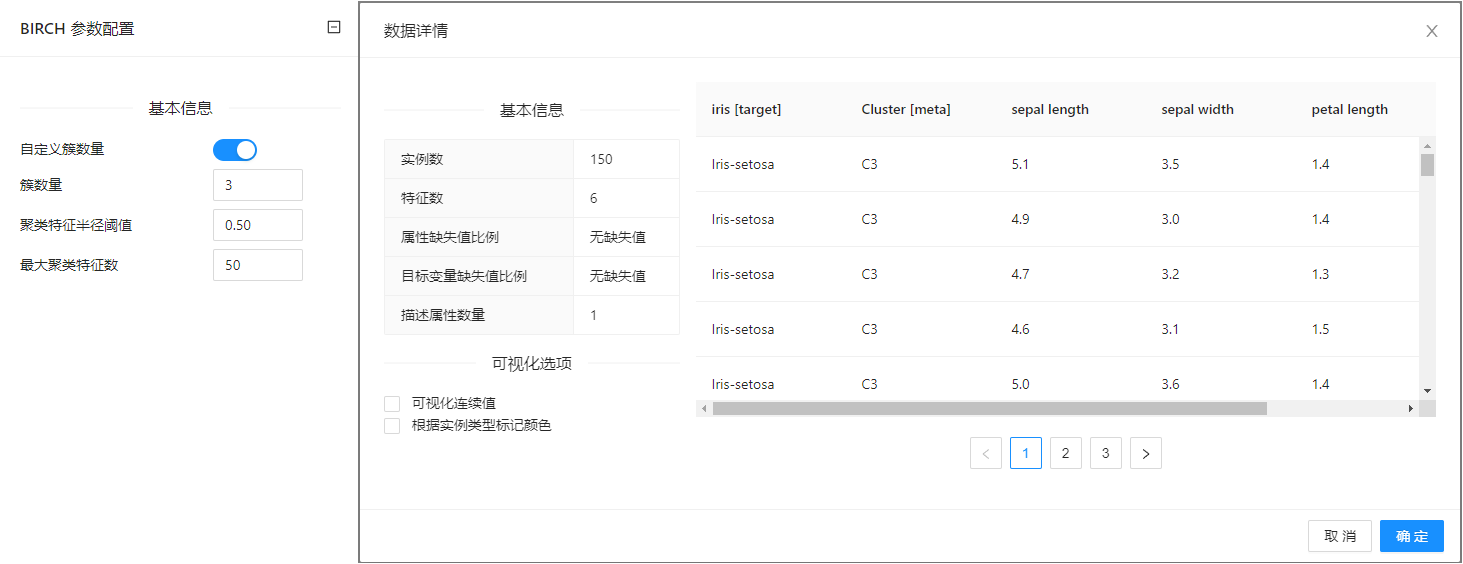
点击 “BIRCH” 控件查看参数配置页面,如下图所示:

参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| 自定义簇数量 | 是否自定义簇数量,如果为否,则根据设置进行聚类自动生成簇数 | true/false | true |
| 簇数量 | 指定簇数量 | 1~1000 | 3 |
| 簇类特征半径阈值 | 实例距离簇中心的距离阈值 | 0.00000001~10000 | 0.5 |
| 最大聚类特征数 | 簇中的最大特征数,如果一个簇的特征数超过这个值会分裂为两个簇 | 1~1000 | 50 |
使用案例
在下图所示的案例中,使用 “加载文件”(File) 控件加载数据集,连接 “BIRCH” 控件进行聚类,之后连接 “查看数据”(Data Table) 控件查看聚类结果。
案例中加载 iris 数据集,案例中控件的配置以及执行结果如下图所示。