二分K均值
组件介绍
“二分K均值(Bisecting KMeans)” 控件使用二分K均值算法对数据进行聚类。
二分K均值算法是k-means聚类算法的一个变体,主要是为了改进k-means算法随机选择初始质心的随机性造成聚类结果不确定性的问题,而Bisecting k-means算法受随机选择初始质心的影响比较小。二分K均值聚类算法的基本思想是,通过引入局部二分试验,每次试验都通过二分具有最大SSE值的一个簇,二分这个簇以后得到的2个子簇,选择2个子簇的总SSE最小的划分方法,这样能够保证每次二分得到的2个簇是比较优的(也可能是最优的),也就是这2个簇的划分可能是局部最优的,取决于试验的次数。
- 输入:
- data:数据集
- 输出:
- data:处理后的数据集
页面介绍
点击 “二分K均值(Bisecting KMeans)” 控件查看参数配置页面,如下图所示:
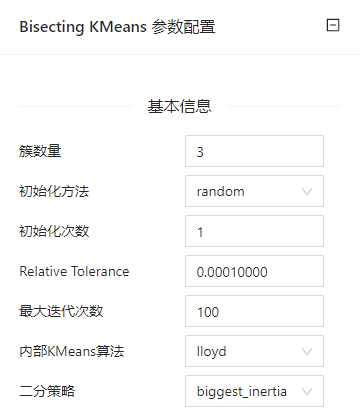
参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| 簇数量 | 指定簇数 | 1~1000 | 2 |
| 初始化方法 | k-means++:k-means++ | k-means++ | random |
| 初始化次数 | 初始化次数,用于产生最佳初始参数 | 1~100 | 1 |
| Relative Tolerance | 连续两次迭代的聚类中心的相对公差,用于判断收敛 | 0.00000001~1 | 0.0001 |
| 最大迭代次数 | 最大迭代次数 | 1~10000 | 100 |
| 内部KMeans算法 | lloyd | lloyd | lloyd |
| 二分策略 | 定义如何执行二分操作 | biggest_inertia | biggest_inertia |
使用案例
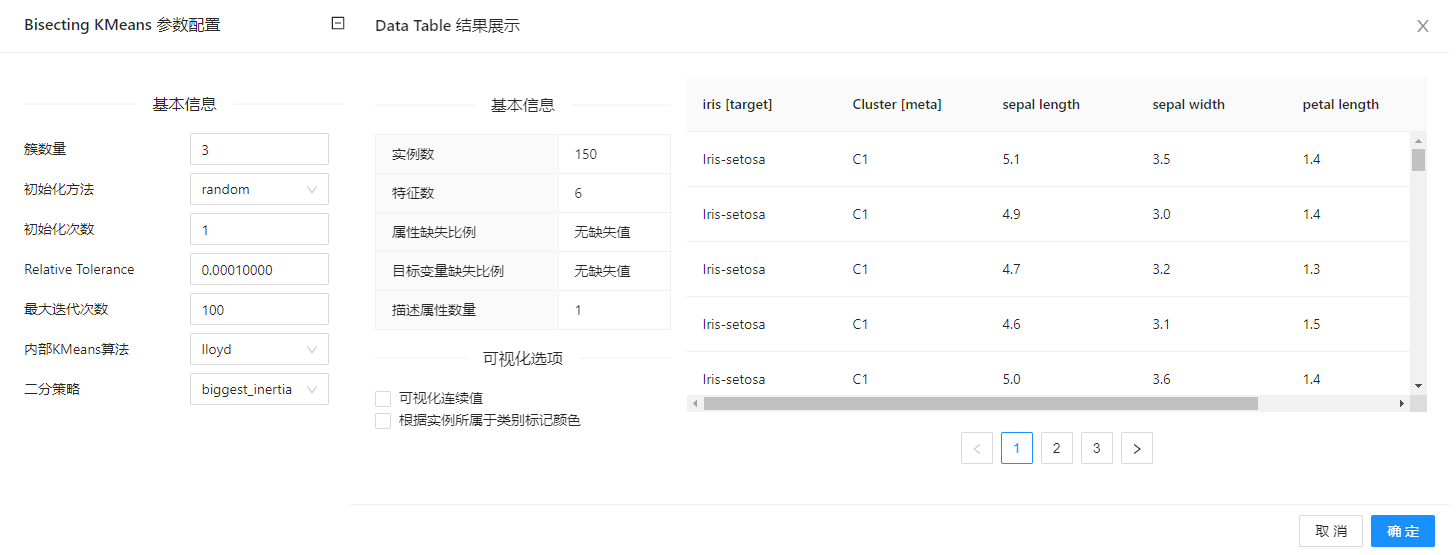
在下图所示的案例中,使用 “加载文件”(File) 控件加载数据集,连接 “二分K均值(Bisecting KMeans)” 控件进行聚类,之后连接 “��查看数据”(Data Table) 控件查看聚类结果。
案例中加载 iris 数据集,案例中控件的配置以及执行结果如下图所示。