K-Means
组件介绍
“K-Means” 控件提供了k-Means 聚类算法对数据进行聚类。
K-Means是一种无监督机器学习算法,它将未标记的数据集分组为不同的簇。
K-Means算法基本步骤如下:
(1) 从数据中选择k个对象作为初始聚类中心;
(2) 计算每个聚类对象到聚类中心的距离来划分;
(3) 再次计算每个聚类中心
(4) 重复上面(2)、(3) 两步操作,直到达到某个中止条件(迭代次数、最小误差变化等)。
- 输入:
- data:数据集
- 输出:
- data:处理后的数据集
- cen:每个簇的中心点
页面介绍
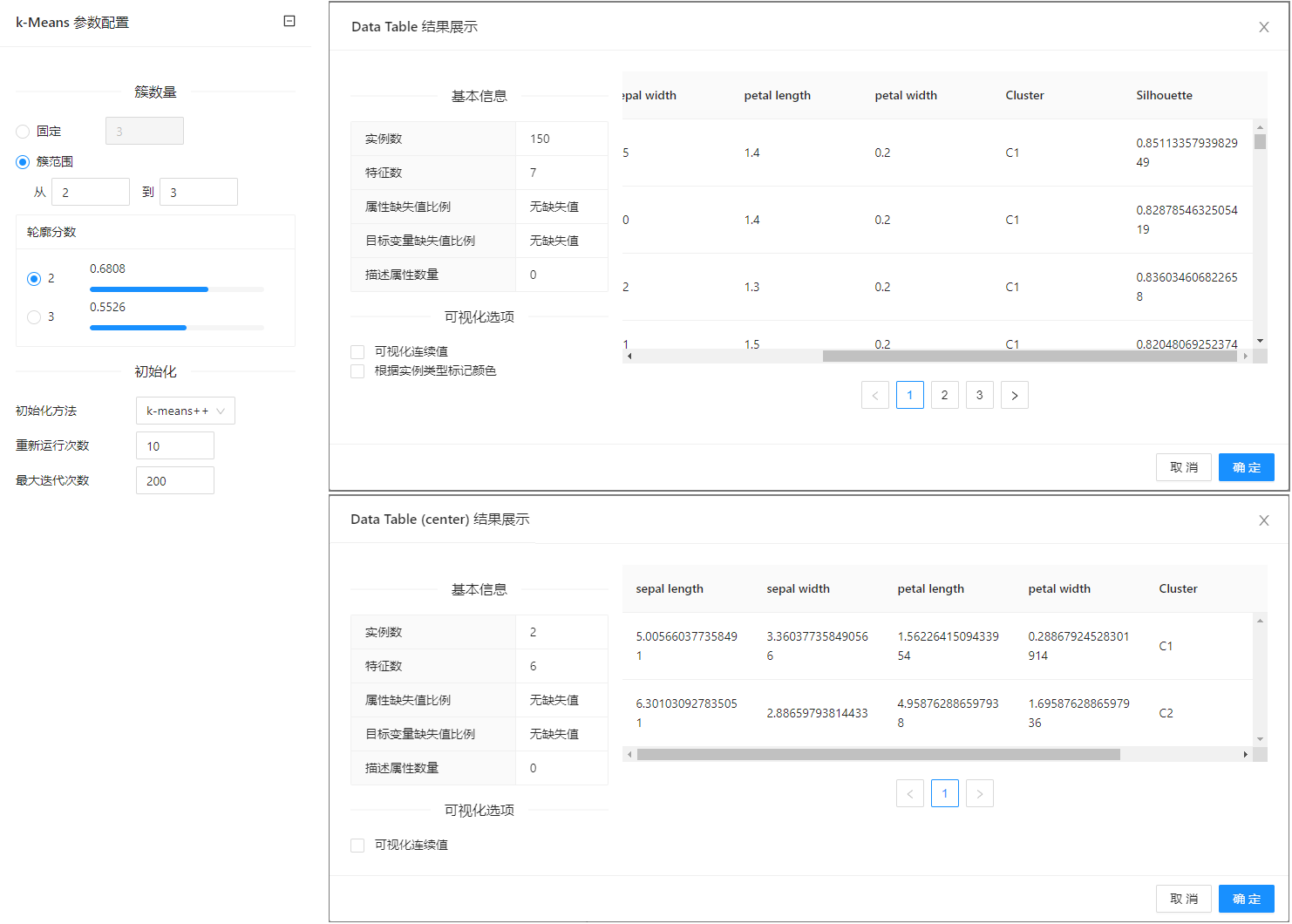
点击 “K-Means” 控件查看参数配置页面,如下图所示:
参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
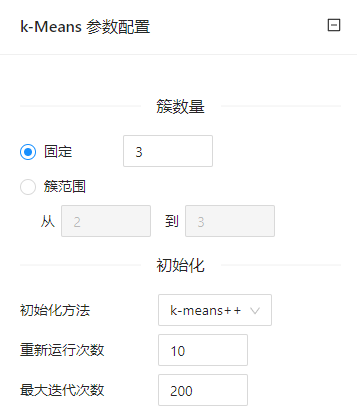
| 簇数量 | 固定:为簇数指定一个固定值 | 固定:1 | 固定:3 |
| 初始化方法 | k-means++:随机选择第一个中心点,然后从剩余点中以与最邻近中心的平方距离成正比的概率选择后续的中心点 | k-means++ | k-means++ |
| 重新运行次数 | 算法运行次数 | 1~10000 | 10 |
| 最大迭代次数 | 算法运行的最大迭代次数 | 1~10000 | 200 |
[详细参数说明](https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html)
使用案例
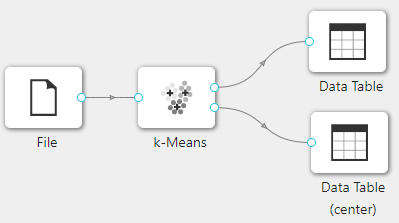
在下图所示的案例中,使用 “加载文件”(File) 控件加载数据集,连接 “K-Means” 控件进行聚类,之后连接 “查看数据”(Data Table) 控件查看聚类结果。
案例中加载 iris 数据集,k-Means 控件中配置簇数量为“从 2 到 3”,其余使用默认配置。案例中控件的配置以及执行结果如下图所示。